The Problem
Cross-border e-discovery in the EU faces substantial complexity from jurisdictional differences, multi-language data, and stringent data privacy laws like GDPR, leading to high costs and delays in litigation and investigations.
Challenges are amplified by GDPR's strict personal data protections, Brussels Regulation jurisdictional rules, blocking statutes, and varying member state requirements, which conflict with discovery needs and require jurisdiction-specific handling, redaction, and privilege logging.
Current solutions rely on manual processes or basic tools lacking integrated automation for semantic routing, compliant redaction, and comprehensive audit trails, resulting in substantial risk, inefficiency, and elevated manual review volumes.
Our Approach
Key elements of this implementation
-
Agentic AI orchestrator with semantic routing to jurisdiction-specific queues based on GDPR legal bases, Brussels Regulation analysis, e-CODEX protocols, and EU AI Act high-risk classifications
-
Automated multi-language processing and per-member-state GDPR redaction with immutable audit trails, privilege logging, and integrations to RelativityOne and EU-based clouds ensuring data residency
-
Compliance controls including EU data residency, tamper-proof logging for all frameworks, automated regulatory reporting under e-CODEX, and human-in-the-loop for reviews below 90% AI confidence with explainability
-
Phased 90-day rollout with 30-day pilot, 2-week training workshops, change champions, and parallel manual/AI operation to address adoption risks and data quality issues
Get the Full Implementation Guide
Unlock full details including architecture and implementation
Implementation Overview
Cross-border e-discovery in the EU faces substantial complexity from jurisdictional differences, multi-language data, and stringent data privacy laws like GDPR, leading to high costs and delays in litigation and investigations[1][2]. Since GDPR's implementation, over 281,000 data breach notifications have been filed across Europe, and many organizations struggle to reconcile cross-border investigations and regional privacy regimes[2]. This orchestrator addresses these challenges through an agentic AI architecture that automates semantic routing, jurisdiction-specific processing, and compliant redaction while maintaining immutable audit trails.
The architecture centres on a multi-agent orchestration layer that ingests documents from diverse sources, classifies them by jurisdiction and legal basis under GDPR Articles 6 and 49, and routes them through appropriate processing pipelines. Each pipeline applies member-state-specific redaction rules, privilege detection, and relevance scoring before documents reach human reviewers. The system integrates with RelativityOne and EU-based cloud infrastructure to ensure data residency compliance, while e-CODEX protocol support enables cross-border judicial cooperation.
Expected outcomes include 40-60% reduction in manual review volume through AI-assisted prioritisation, near-elimination of jurisdictional routing errors, and comprehensive audit trails satisfying both GDPR accountability requirements and EU AI Act transparency obligations for high-risk AI systems. The architecture supports human-in-the-loop review for all outputs below 90% confidence, ensuring legal defensibility while maximising automation benefits.
UI Mockups
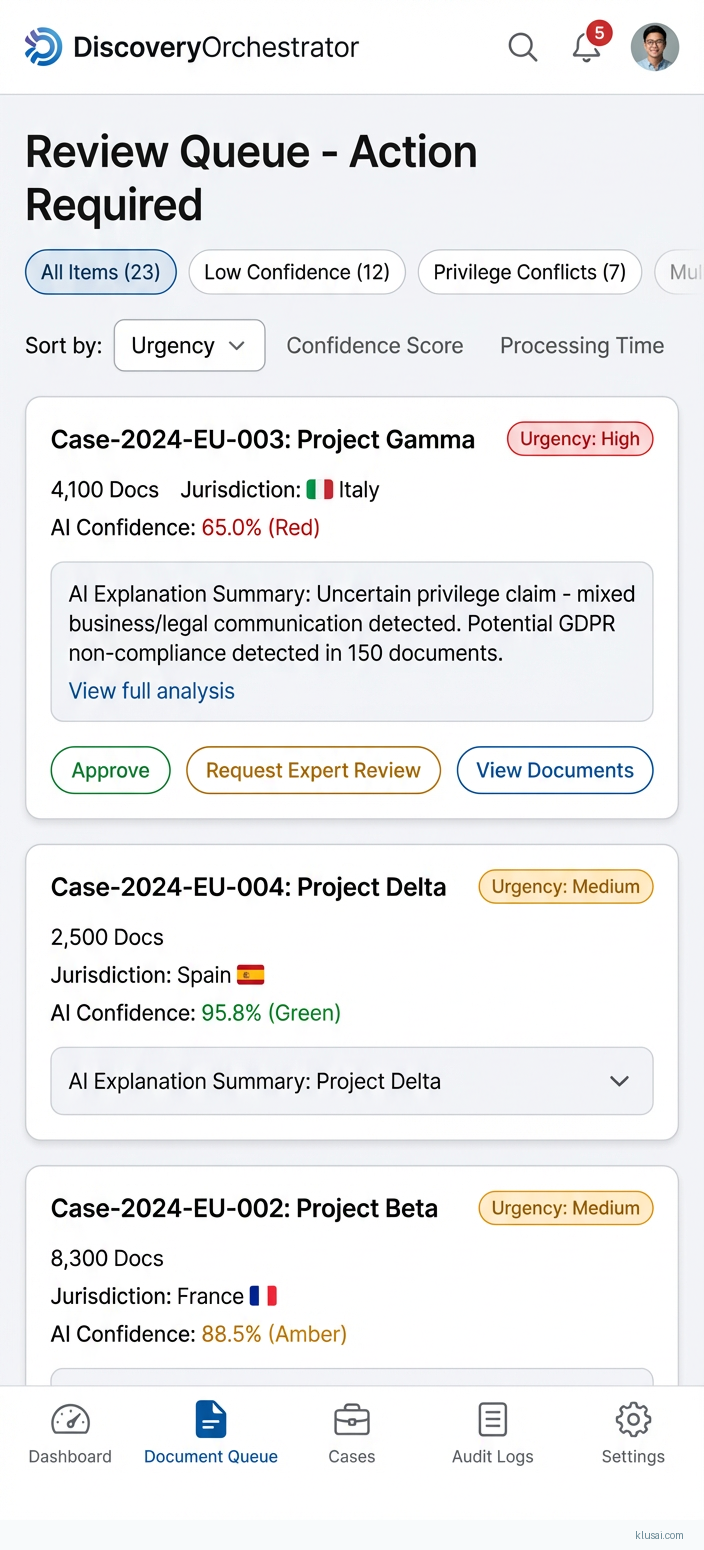
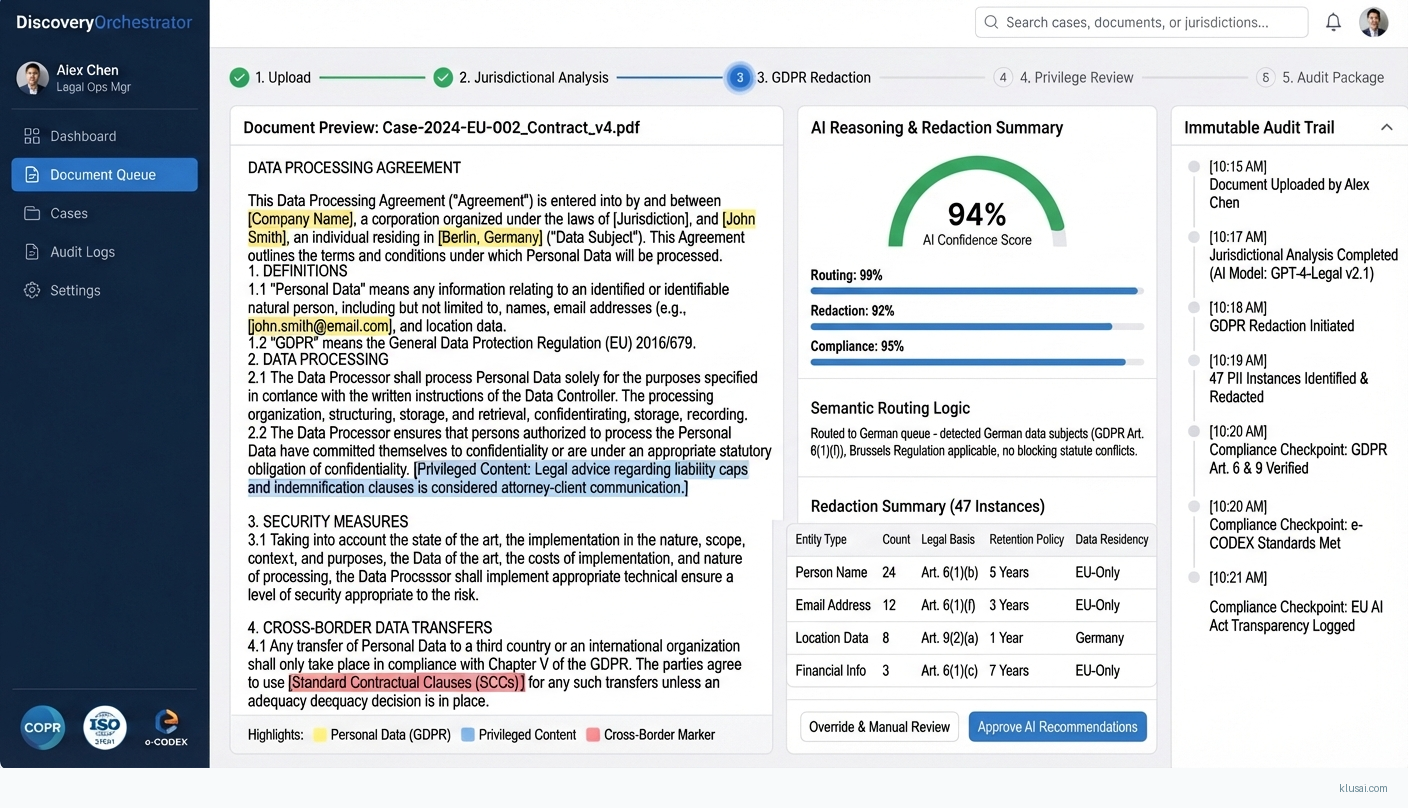
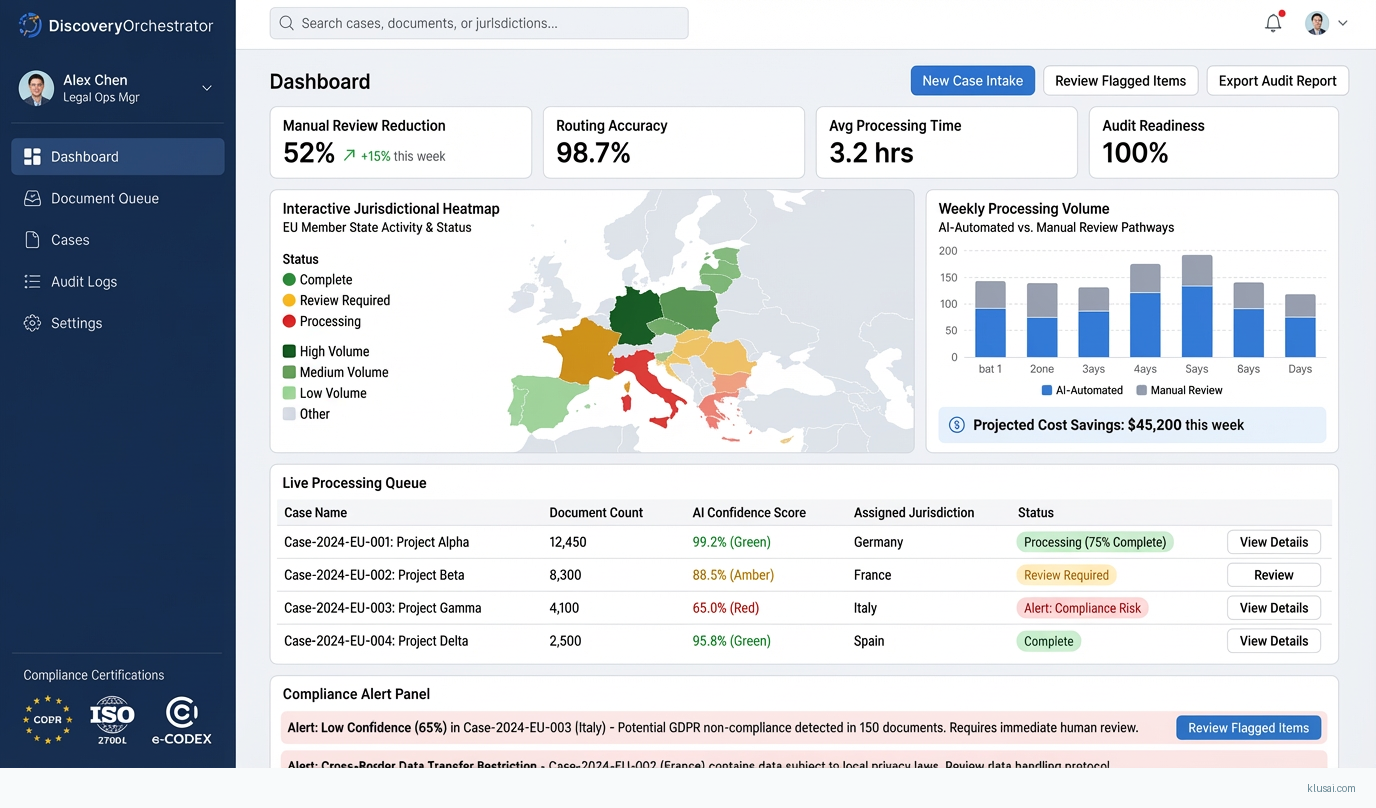
System Architecture
The architecture comprises four primary layers: ingestion, orchestration, processing, and output. The ingestion layer connects to enterprise content sources including Microsoft 365, on-premises file shares, and custodian mobile devices through secure connectors that maintain chain of custody metadata. Documents flow into a staging area within EU-resident cloud infrastructure before any processing occurs, ensuring GDPR territorial requirements are met from first contact.
The orchestration layer implements an agentic AI coordinator that analyses each document's metadata and content to determine jurisdiction, applicable legal bases, and processing requirements. This agent consults a knowledge graph encoding Brussels Regulation jurisdictional rules, member-state blocking statutes, and GDPR derogation provisions to route documents to appropriate processing queues. The orchestrator also manages workflow state, retry logic, and escalation paths for edge cases requiring legal team intervention.
The processing layer contains specialised agents for distinct tasks: multi-language NLP for semantic analysis across EU official languages, privilege detection using fine-tuned legal language models, PII identification and redaction calibrated to member-state requirements, and relevance scoring against matter-specific criteria. Each agent produces confidence scores and explainability outputs that feed into the human review interface. Processing occurs on GPU-accelerated compute within EU data centres, with vector embeddings stored in EU-resident indices.
The output layer integrates with RelativityOne through its REST API for document production, generates e-CODEX-compliant packages for cross-border judicial requests, and maintains tamper-proof audit logs using append-only storage with cryptographic verification. All outputs include provenance metadata linking back to source documents and processing decisions, satisfying both litigation hold requirements and GDPR accountability obligations.
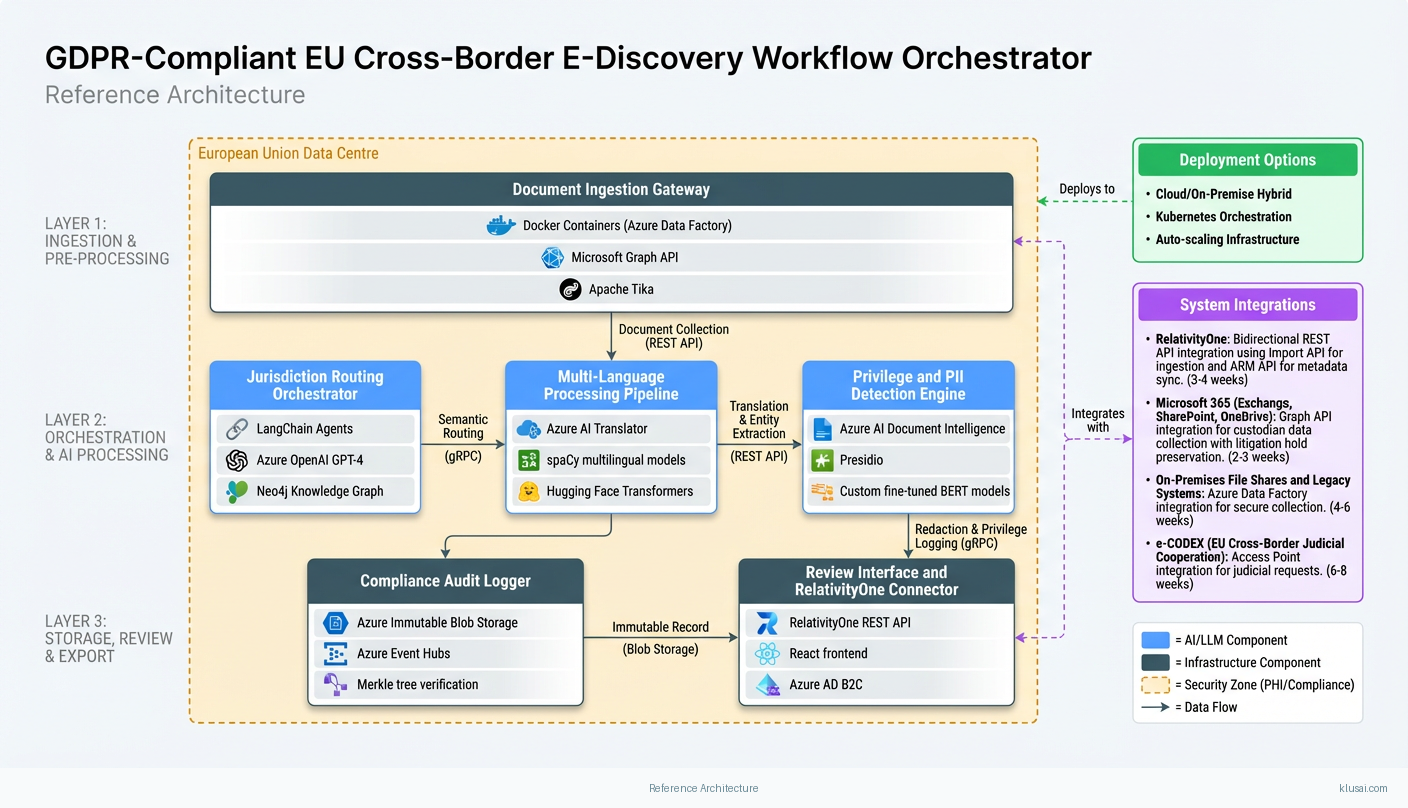
Key Components
| Component | Purpose | Technologies |
|---|---|---|
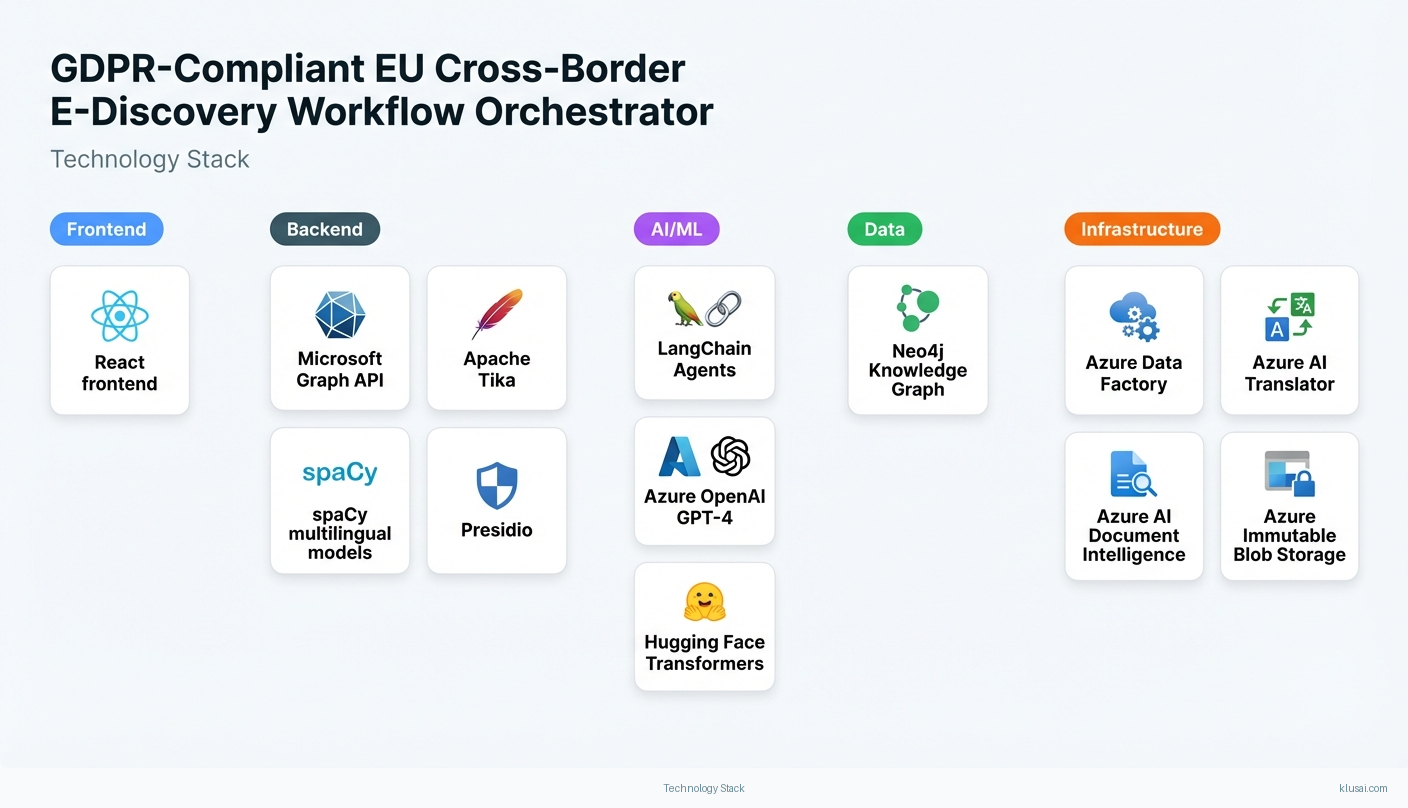
| Document Ingestion Gateway | Secure collection of documents from enterprise sources with chain of custody preservation and initial metadata extraction | Azure Data Factory Microsoft Graph Api Apache Tika |
| Jurisdiction Routing Orchestrator | Agentic AI coordinator that analyses documents and routes to jurisdiction-specific processing queues based on GDPR legal bases and Brussels Regulation rules | Langchain Agents Azure Openai Gpt 4 Neo4J Knowledge Graph |
| Multi-Language Processing Pipeline | Semantic analysis, translation, and entity extraction across all 24 EU official languages | Azure Ai Translator Spacy Multilingual Models Hugging Face Transformers |
| Privilege and PII Detection Engine | Identifies privileged communications and personal data requiring redaction, with jurisdiction-specific rules | Azure Ai Document Intelligence Presidio Custom Fine Tuned Bert Models |
| Compliance Audit Logger | Maintains immutable, tamper-proof records of all processing decisions with cryptographic verification | Azure Immutable Blob Storage Azure Event Hubs Merkle Tree Verification |
| Review Interface and RelativityOne Connector | Human-in-the-loop review interface with explainability and bidirectional sync to RelativityOne | Relativityone Rest Api React Frontend Azure Ad B2C |
Technology Stack
Implementation Phases
Foundation and Pilot Configuration
Deploy core infrastructure in EU-West Azure region with security hardening and compliance controls
- • Deploy core infrastructure in EU-West Azure region with security hardening and compliance controls
- • Configure jurisdiction routing rules for 3 pilot member states (Germany, France, Netherlands)
- • Establish RelativityOne integration and validate bidirectional document sync
- Production-ready Azure environment with VNet, private endpoints, and immutable storage
- Jurisdiction knowledge graph with GDPR legal bases and Brussels Regulation rules for pilot states
- Working RelativityOne connector with test matter synchronisation
Processing Pipeline Development
Deploy multi-language NLP pipeline with support for pilot jurisdiction languages
- • Deploy multi-language NLP pipeline with support for pilot jurisdiction languages
- • Implement privilege detection model with fine-tuning on EU legal communications corpus
- • Build PII detection and redaction engine with member-state-specific patterns
- Multi-language processing pipeline handling German, French, Dutch, and English documents
- Privilege detection model achieving >90% recall on validation set with explainability outputs
- PII redaction engine with configurable rules per jurisdiction and audit trail integration
Integration and Controlled Pilot
Execute parallel operation with manual processes on live matter subset
- • Execute parallel operation with manual processes on live matter subset
- • Validate end-to-end workflow from ingestion through production with legal team sign-off
- • Conduct training workshops for legal operations and review teams
- Pilot completion report with accuracy metrics, processing times, and user feedback
- Trained cohort of 10-15 users across legal operations and review teams
- Documented runbooks for common workflows and exception handling
Expansion and Optimisation
Extend jurisdiction coverage to remaining EU member states based on client priority
- • Extend jurisdiction coverage to remaining EU member states based on client priority
- • Implement e-CODEX protocol support for cross-border judicial cooperation requests
- • Optimise processing throughput and cost based on pilot learnings
- Full 27 member-state jurisdiction support with validated routing rules
- e-CODEX-compliant document package generation for judicial requests
- Performance-optimised system achieving target throughput with documented cost model
Key Technical Decisions
Should we use a single multi-tenant deployment or isolated per-client infrastructure?
Cross-border e-discovery involves highly sensitive litigation data with strict confidentiality requirements. Client isolation ensures no risk of data leakage between matters or organisations, simplifies GDPR data controller responsibilities, and enables client-specific retention policies. The additional infrastructure cost is justified by reduced legal risk and simplified compliance posture.
- Complete data isolation eliminates cross-client confidentiality risks
- Simplified GDPR compliance with clear data controller boundaries
- Higher infrastructure costs compared to multi-tenant architecture
- More complex deployment and update processes across client instances
Should privilege detection use a fine-tuned specialist model or general-purpose LLM with prompting?
Privilege detection requires consistent, auditable decisions with high recall to avoid waiving privilege. A fine-tuned model provides deterministic outputs, lower latency, and reduced per-document costs compared to LLM inference. The LLM fallback handles documents where the specialist model confidence is below threshold, providing best-of-both-worlds coverage while maintaining cost efficiency for the majority of documents.
- Lower latency and cost for high-volume processing
- More consistent and auditable decision patterns
- Requires investment in training data curation and model maintenance
- Less adaptable to novel privilege patterns without retraining
How should we handle documents spanning multiple jurisdictions?
Documents involving multiple EU jurisdictions (e.g., email thread between German and French entities) present complex compliance scenarios. Routing to the most restrictive applicable jurisdiction ensures GDPR compliance while flagging for secondary review allows jurisdiction-specific nuances to be addressed. This conservative approach prioritises compliance over processing efficiency.
- Ensures compliance with strictest applicable requirements
- Reduces risk of jurisdictional compliance failures
- May result in over-redaction in some cases
- Increases human review volume for multi-jurisdiction documents
Should audit logs use blockchain or traditional immutable storage?
While blockchain provides strong tamper-evidence, it introduces complexity, cost, and potential GDPR right-to-erasure conflicts. Azure Immutable Blob Storage with legal hold policies provides equivalent tamper-proofing for audit purposes, with Merkle tree verification enabling cryptographic proof of log integrity. This approach satisfies regulatory requirements while maintaining operational simplicity and GDPR compatibility.
- Simpler operations and lower cost than blockchain alternatives
- Native integration with Azure compliance and legal hold features
- Less decentralised verification compared to blockchain
- Dependent on Azure platform availability and policies
Integration Patterns
| System | Approach | Complexity | Timeline |
|---|---|---|---|
| RelativityOne | Bidirectional REST API integration using RelativityOne's Import API for document ingestion and ARM API for metadata sync. Documents processed by the orchestrator are pushed to RelativityOne workspaces with AI-generated coding fields, confidence scores, and processing metadata. Review decisions in RelativityOne sync back to update orchestrator state and refine models. | medium | 3-4 weeks |
| Microsoft 365 (Exchange, SharePoint, OneDrive) | Microsoft Graph API integration for custodian data collection with litigation hold preservation. Incremental collection using delta queries minimises data transfer and supports ongoing collection during active matters. Azure AD integration provides SSO and ensures collection respects existing access controls. | medium | 2-3 weeks |
| On-Premises File Shares and Legacy Systems | Azure Data Factory with self-hosted integration runtime for secure collection from on-premises sources. Supports SMB file shares, legacy document management systems via ODBC, and custom connectors for proprietary systems. Data remains encrypted in transit and at rest throughout collection. | high | 4-6 weeks |
| e-CODEX (EU Cross-Border Judicial Cooperation) | Implementation of e-CODEX Access Point integration for receiving and responding to cross-border judicial requests. Document packages formatted according to e-CODEX technical specifications with appropriate metadata schemas. Supports European Investigation Order (EIO) workflows and Mutual Legal Assistance requests. | high | 6-8 weeks |
ROI Framework
ROI is driven by reduction in manual document review hours, decreased outside counsel spend on routine classification tasks, and risk mitigation from consistent GDPR compliance. The framework calculates annual benefit from review hour reduction against platform and implementation costs[5][7].
Key Variables
Example Calculation
Build vs. Buy Analysis
Internal Build Effort
Internal build would require 18-24 months with a dedicated team of 6-8 engineers including NLP specialists, legal technology experts, and compliance architects. Key challenges include maintaining currency with evolving GDPR interpretations across 27 member states, building and maintaining multi-language NLP models, and achieving the integration depth required for production legal workflows. Estimated internal build cost €800K-1.2M before ongoing maintenance.
Market Alternatives
RelativityOne with Relativity aiR
€200-400K annually depending on data volume and user countMarket-leading e-discovery platform with native AI capabilities for privilege and relevance review
- • Deep integration with existing Relativity workflows
- • Established market presence and legal team familiarity
- • Continuous AI model updates from Relativity
- • Limited customisation for jurisdiction-specific GDPR requirements
- • Less flexibility for non-standard workflows or integrations
- • Dependency on Relativity's AI development roadmap
Reveal AI (Brainspace)
€150-300K annually for enterprise deploymentAI-powered e-discovery with strong analytics and visualisation capabilities
- • Strong conceptual analytics and clustering capabilities
- • Good multi-language support for major EU languages
- • Flexible deployment options including on-premises
- • Requires significant configuration for GDPR-specific workflows
- • Less mature jurisdiction-aware routing capabilities
- • Integration with e-CODEX would require custom development
Disco Cecilia
€100-250K annually based on usageCloud-native e-discovery with AI-first approach and modern user experience
- • Modern architecture with rapid innovation pace
- • Strong AI capabilities for document classification
- • Competitive pricing for cloud-native deployment
- • Primarily US-focused; EU-specific features less mature
- • Data residency options more limited than Azure-native solutions
- • Smaller partner ecosystem in EU market
Our Positioning
KlusAI's approach is optimal for organisations requiring deep customisation of jurisdiction-specific workflows, integration with existing enterprise systems beyond standard e-discovery platforms, or compliance with emerging regulations like the EU AI Act. We assemble teams with specific expertise in EU legal technology, GDPR compliance, and cross-border litigation support, delivering a tailored solution that evolves with your requirements rather than constraining you to a vendor's product roadmap.
Team Composition
KlusAI assembles a cross-functional team combining legal technology expertise, NLP engineering, and EU regulatory knowledge. Team composition scales based on implementation phase, with peak staffing during processing pipeline development.
| Role | FTE | Focus |
|---|---|---|
| Solution Architect | 1.0 | Overall architecture design, Azure infrastructure, security controls, and integration patterns |
| NLP/ML Engineer | 1.5 | Multi-language processing pipeline, privilege detection model training, and confidence calibration |
| Legal Technology Specialist | 0.75 | RelativityOne integration, e-discovery workflow design, and legal team training |
| Compliance Engineer | 0.5 | GDPR compliance controls, audit logging, EU AI Act requirements, and e-CODEX integration |
| Project Manager | 0.5 | Delivery coordination, risk management, stakeholder communication, and change management |
Supporting Evidence
Performance Targets
40-60% reduction in documents requiring full manual review
>98% correct routing on first pass
<4 hours end-to-end for standard bundles
100% of processing decisions logged with full provenance and explainability
Team Qualifications
- KlusAI's network includes professionals with extensive experience in EU legal technology implementations, including cross-border e-discovery and GDPR compliance projects
- Our teams are assembled with specific expertise in multi-language NLP, having worked with legal document processing across major EU languages
- We bring together technical specialists familiar with RelativityOne integration patterns and EU data residency requirements for legal sector deployments
Source Citations
Cross-border e-discovery in the EU faces substantial complexity from jurisdictional differences, multi-language data, and stringent data privacy laws like GDPR, leading to high costs and delays
directionalover 281,000 data breach notifications have been filed across Europe since GDPR; organizations struggle to reconcile cross-border investigations and regional privacy regimes
"since GDPR's implementation, over 281,000 data breach notifications have been filed across Europe? Many organizations struggle to reconcile cross-border investigations and regional privacy regimes"exact
challenges arising from cross border e-discovery in a data protection context... ensuring the timely involvement of e-discovery specialists... managing the extra time needed to meet the requirements of European data protection legislation
directionalcompanies conducting e-discovery in the EU must comply with GDPR, which has strict data protection and privacy requirements... Compliance with various legal requirements, data privacy laws, and language barriers makes this process inherently complex
directionalDue to rising globalization and the focus on data privacy rights, the challenges of cross-border eDiscovery will continue to increase over time... corporations that invest the time in building internal processes... will be able to significantly reduce the risk and cost
directionalManaging cross-border eDiscovery manually is nearly impossible due to the sheer volume of data... Advanced eDiscovery tools can help streamline... These tools can automate much of the process, significantly reducing the risk of human error
directionalReady to discuss?
Let's talk about how this could work for your organization.
Schedule a Consultation
Pick a date that works for you
Times shown in your local timezone ()
Prefer email? Contact us directly
Almost there!
at
Your details
at
You're all set!
Check your email for confirmation and calendar invite.
Your booking is confirmed! Our team will reach out to confirm the details.
Your consultation
· min
( team time)
Quick Overview
- Technology
- Process Automation
- Complexity
- high
- Timeline
- 4-6 months
- Industry
- Legal Services
- Region
- European Union