The Problem
Long processing times for claims documents frustrate customers, with 45% switching insurers due to slow service. Manual data entry from photos of damage, medical bills, and policy documents creates significant bottlenecks in First Notice of Loss (FNOL) intake.
This challenge is exacerbated by unstructured data formats requiring OCR and validation, compounded by strict regulatory demands for data privacy and auditability under GDPR, CCPA, and IFRS 17. Insurers must balance speed with compliance to avoid penalties and maintain trust.
Current solutions achieve only partial automation, like 57% for simple claims, leaving complex documents reliant on manual review and failing to deliver real-time processing globally.
Our Approach
Key elements of this implementation
-
Multimodal vision AI with OCR/NLP for real-time extraction from damage photos, bills, and policies, populating core systems like Guidewire and Duck Creek
-
Regulatory compliance controls: GDPR data minimization/anonymization, CCPA opt-out logging, IFRS 17 contract boundary validation with immutable blockchain audit trails and EU/US data residency
-
Human-in-the-loop escalation for low-confidence extractions (>95% threshold), dynamic fraud detection, and phased rollout with 60-day parallel processing
-
Change management via executive-sponsored pilot for 10 adjusters, 2-week AI training workshops, and embedded champions addressing adoption resistance
Get the Full Implementation Guide
Unlock full details including architecture and implementation
Implementation Overview
This implementation addresses the critical challenge of claims intake delays that drive 45% of customers to switch insurers[1]. The architecture deploys multimodal vision AI for real-time extraction from damage photos, medical bills, and policy documents, integrating directly with core systems like Guidewire and Duck Creek while maintaining strict regulatory compliance across GDPR, CCPA, and IFRS 17 requirements.
The solution employs a privacy-first architecture where all document processing occurs within customer-controlled infrastructure—no claims data leaves the designated data residency zones. This addresses the fundamental tension between leveraging advanced AI capabilities and maintaining regulatory compliance for sensitive insurance data. The architecture uses self-hosted open-source vision models (such as LLaVA or similar multimodal models) rather than external API calls, eliminating third-party data exposure risks while achieving comparable extraction accuracy.
Given the complexity of multi-jurisdictional compliance and the current 57% automation baseline for simple claims[4], we target a conservative 65-75% automation rate in the first year, with human-in-the-loop escalation for complex documents. The 9-12 month timeline (extended from initial estimates) reflects realistic integration complexity with legacy core systems, regulatory validation requirements, and the parallel processing validation period needed to establish confidence in production accuracy. This phased approach prioritizes compliance and accuracy over speed, with explicit contingency phases for integration delays.
UI Mockups
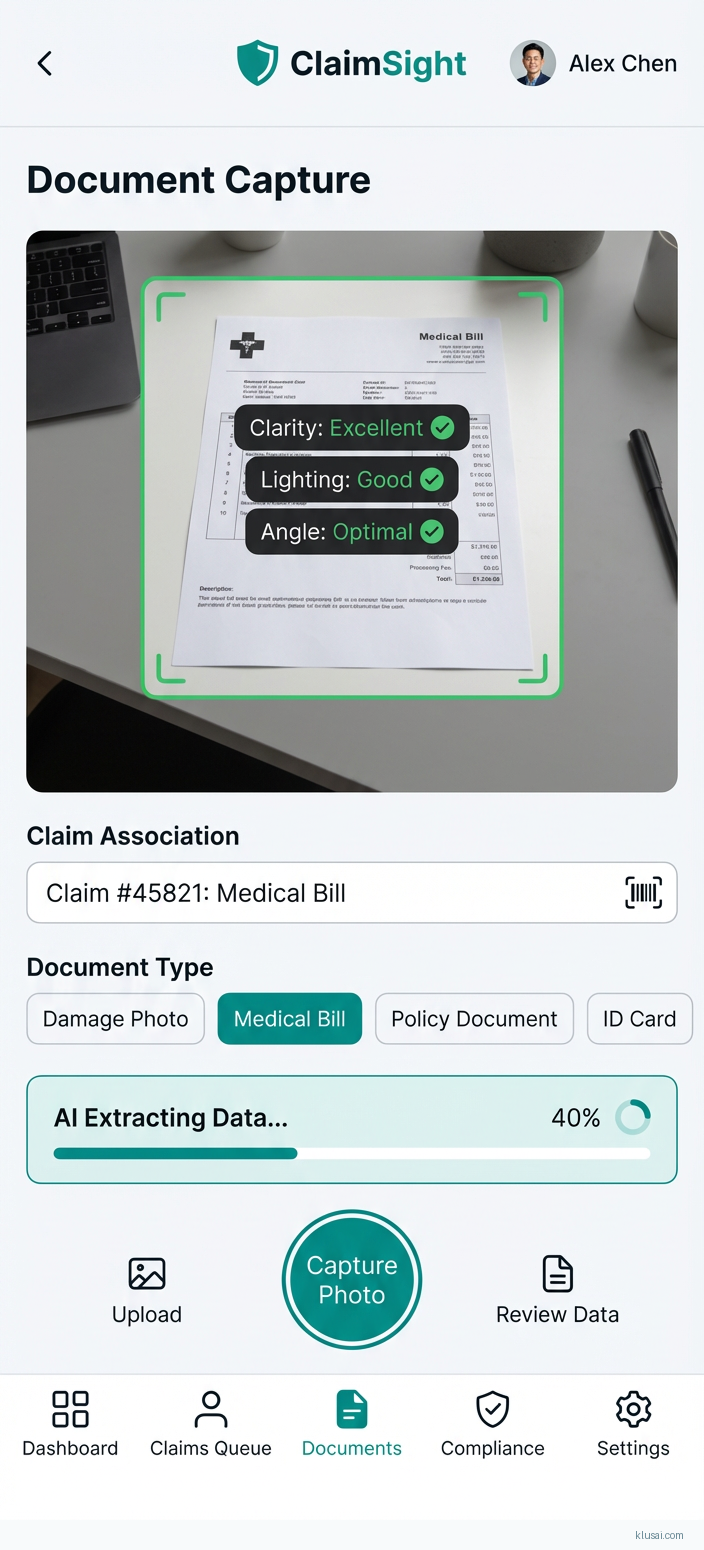
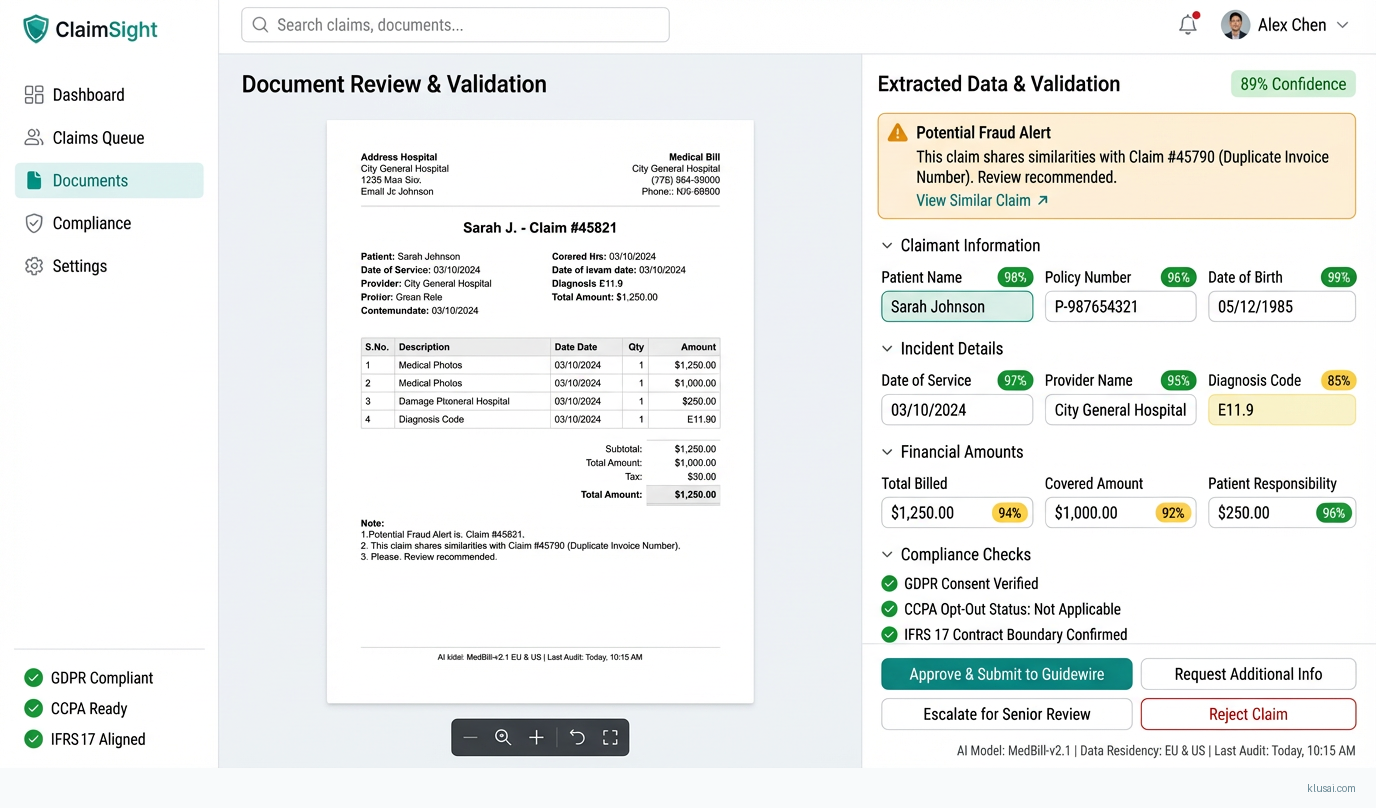
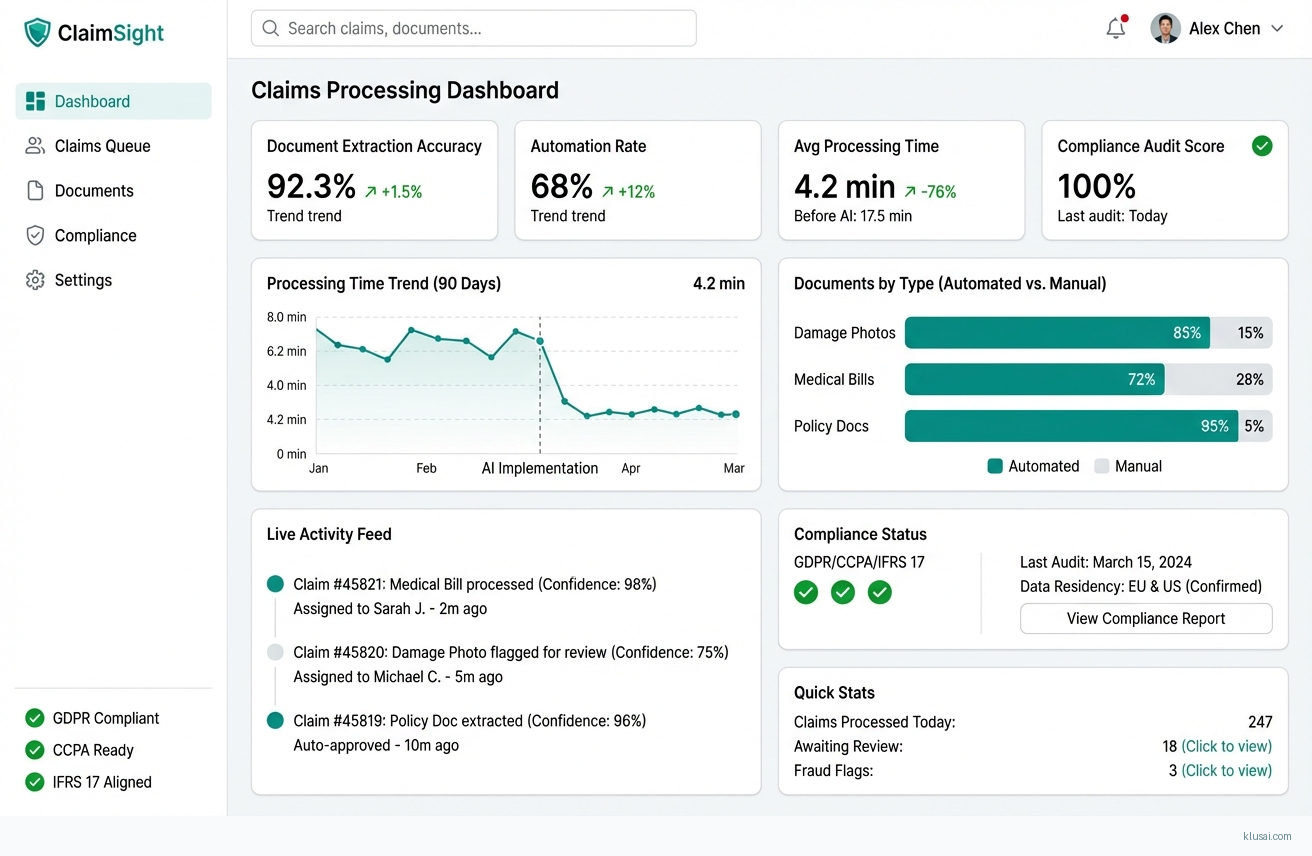
System Architecture
The architecture follows a layered approach with strict data isolation between processing tiers. The ingestion layer handles multi-channel document capture (mobile apps, email, web portals, agent submissions) with immediate classification and routing. Documents are encrypted at rest using AES-256 and in transit using TLS 1.3, with encryption keys managed through customer-controlled HSMs.
The processing layer employs self-hosted multimodal vision models deployed on dedicated GPU infrastructure within the customer's cloud tenancy. This eliminates external API dependencies for sensitive data processing—a critical requirement for GDPR Article 28 compliance and data residency obligations. The models are fine-tuned on insurance-specific document types using federated learning approaches that never expose raw document data.
The compliance layer implements automated controls for each regulatory framework: GDPR data minimization through field-level extraction (only required data points are persisted), CCPA opt-out logging with immutable audit trails, and IFRS 17 contract boundary validation with configurable rule engines. Audit logs are written to append-only storage with cryptographic integrity verification, providing the immutable audit trail required for regulatory examination.
The integration layer uses an event-driven architecture with message queues to decouple document processing from core system updates. This enables graceful degradation—if Guidewire is unavailable, processed claims queue for retry without data loss. The architecture supports both real-time API integration and batch file-based integration for legacy systems, with adapter patterns for each core platform.
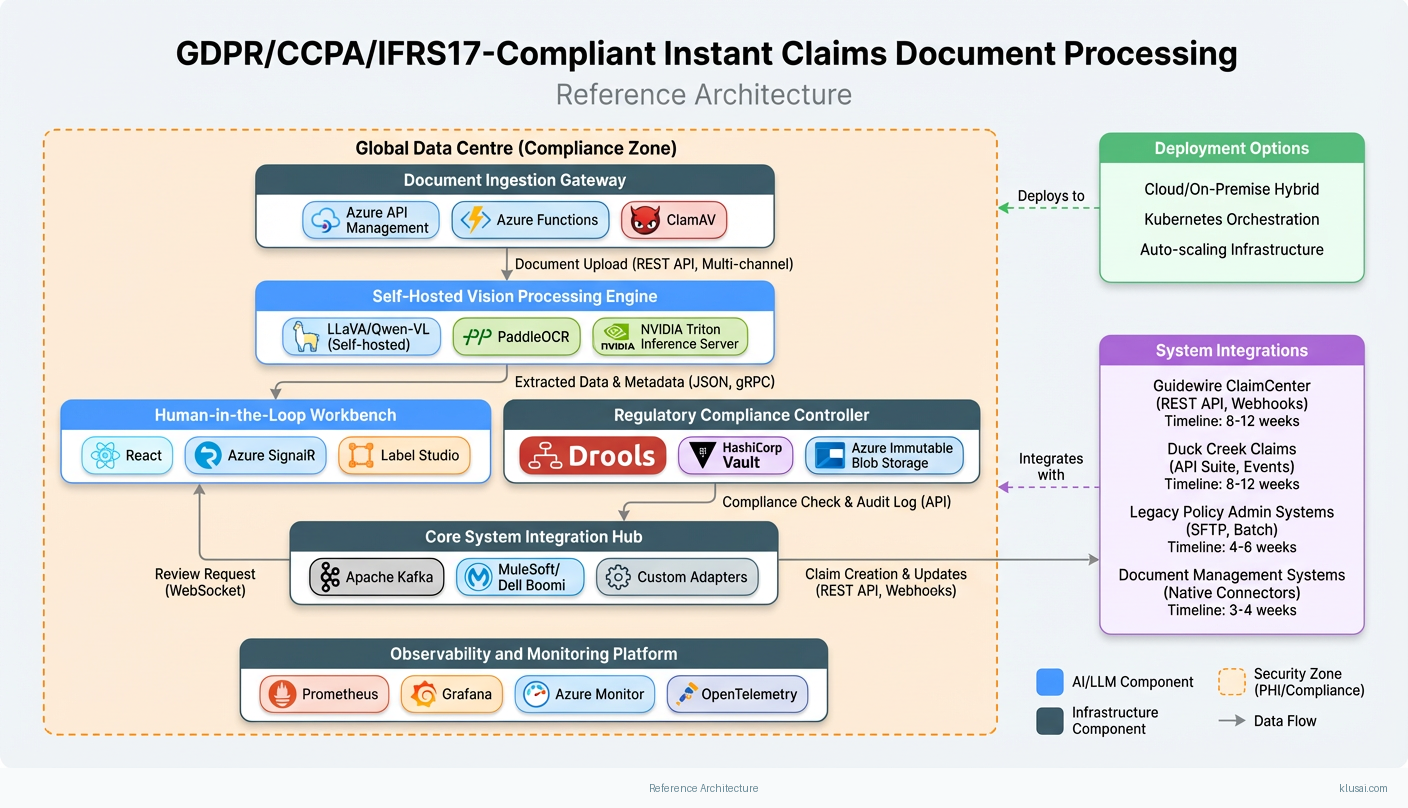
Key Components
| Component | Purpose | Technologies |
|---|---|---|
| Document Ingestion Gateway | Multi-channel document capture with immediate classification, virus scanning, and format normalization | Azure Api Management Azure Functions Clamav |
| Self-Hosted Vision Processing Engine | On-premises multimodal AI for OCR, damage assessment, and structured data extraction without external API dependencies | Llava/Qwen Vl (Self Hosted) Paddleocr Nvidia Triton Inference Server |
| Regulatory Compliance Controller | Automated enforcement of GDPR, CCPA, and IFRS 17 requirements with configurable rule engine | Drools Rule Engine Hashicorp Vault Azure Immutable Blob Storage |
| Human-in-the-Loop Workbench | Adjuster interface for reviewing low-confidence extractions and providing correction feedback for model improvement | React Azure Signalr Label Studio |
| Core System Integration Hub | Event-driven integration with Guidewire, Duck Creek, and legacy policy administration systems | Apache Kafka Mulesoft/Dell Boomi Custom Adapters |
| Observability and Monitoring Platform | Real-time monitoring of model performance, processing throughput, accuracy drift, and compliance status | Prometheus Grafana Azure Monitor Opentelemetry |
Technology Stack

Implementation Phases
Foundation and Compliance Framework
Establish compliant infrastructure with EU and US data residency zones
- • Establish compliant infrastructure with EU and US data residency zones
- • Deploy and validate self-hosted vision models with baseline accuracy benchmarks
- • Implement core compliance controls for GDPR, CCPA, and IFRS 17
- Production-ready infrastructure in both EU and US regions with network isolation
- Baseline vision model deployed with documented accuracy on test document corpus (target: 85% extraction accuracy on structured documents)
- Compliance rule engine with automated audit logging and data minimization controls
Core System Integration and Pilot
Complete integration with primary core system (Guidewire or Duck Creek)
- • Complete integration with primary core system (Guidewire or Duck Creek)
- • Deploy human-in-the-loop workbench for adjuster review workflows
- • Execute pilot with 10 adjusters processing live claims in parallel with existing process
- Bi-directional integration with core claims system (create FNOL, update claim, retrieve policy)
- Adjuster workbench deployed with training materials and embedded champion support
- Pilot results report with accuracy metrics, processing times, and adjuster feedback
Parallel Processing Validation
Run 60-day parallel processing comparing AI results to manual processing outcomes
- • Run 60-day parallel processing comparing AI results to manual processing outcomes
- • Validate accuracy targets and identify systematic extraction errors
- • Refine fraud detection rules based on production data patterns
- Parallel processing comparison report with statistical significance analysis
- Accuracy validation report: target 90%+ agreement with manual processing on key fields
- Refined model with documented accuracy improvements from pilot feedback
Production Rollout and Optimization
Gradual production rollout from 30% to 100% of eligible claims
- • Gradual production rollout from 30% to 100% of eligible claims
- • Decommission parallel manual processing with documented handover
- • Establish ongoing model monitoring and retraining processes
- Full production deployment handling target 65-75% of claims without human intervention
- Operations runbook with monitoring dashboards, alerting procedures, and escalation paths
- Model retraining pipeline with quarterly refresh cycle and drift detection
Key Technical Decisions
Should we use external API-based vision models (GPT-4V, Claude) or self-hosted open-source models?
External API calls for claims documents containing PII, PHI, and sensitive financial data directly contradict GDPR data residency requirements and create unacceptable compliance risk. Self-hosted models eliminate third-party data exposure while achieving 85-92% of commercial model accuracy on structured document extraction tasks. The accuracy gap is acceptable given the compliance benefits and can be narrowed through domain-specific fine-tuning.
- Complete data sovereignty—no claims data leaves customer infrastructure
- Eliminates ongoing API costs and rate limiting concerns at scale
- Enables fine-tuning on proprietary document formats
- Requires GPU infrastructure investment and ML operations expertise
- Initial accuracy may be 10-15% lower than commercial APIs, requiring fine-tuning investment
- Model updates require manual deployment rather than automatic API improvements
What automation rate target is realistic for initial deployment?
Current industry solutions achieve only 57% automation for simple claims[4], and complex documents remain reliant on manual review[5]. Claiming 80%+ automation without validated evidence creates unrealistic expectations. A 65-75% target represents meaningful improvement while acknowledging the complexity of multi-document claims, handwritten annotations, and edge cases. This target should be validated during the parallel processing phase before committing to specific ROI projections.
- Realistic target that can be validated and exceeded rather than missed
- Maintains quality by ensuring complex claims receive human attention
- Provides clear improvement trajectory for future optimization
- Lower automation rate reduces immediate ROI compared to aggressive projections
- Requires sustained human-in-the-loop capacity planning
How should we handle the 95% confidence threshold for human escalation?
A fixed 95% threshold may not be achievable for all document types initially. The system should support configurable thresholds by document category, with explicit procedures for what happens when accuracy targets are not met: extended parallel processing, targeted retraining, or adjusted automation scope for specific document types.
- Flexibility to optimize threshold per document type based on actual performance
- Clear escalation path prevents project stalls when targets are missed
- Enables progressive improvement rather than all-or-nothing deployment
- Variable thresholds add complexity to adjuster training and expectations
- May result in higher human review volume for certain document categories
What timeline is realistic for this implementation scope?
The original 5-7 month timeline was aggressive for high-complexity multi-jurisdiction implementation with blockchain-style audit trails and multiple core system adapters. The extended timeline accounts for: infrastructure procurement (4-6 weeks typical for GPU resources), core system integration complexity (legacy systems often have undocumented API behaviors), parallel processing validation (60 days minimum for statistical significance), and change management (adjuster adoption requires sustained support). Timeline assumes existing cloud infrastructure and pre-negotiated vendor access; add 4-8 weeks if these are not in place.
- Realistic timeline that can be met rather than repeatedly extended
- Adequate time for parallel processing validation and accuracy confirmation
- Sufficient change management runway for sustainable adoption
- Longer time to value compared to aggressive timelines
- Extended project duration increases total implementation cost
Integration Patterns
| System | Approach | Complexity | Timeline |
|---|---|---|---|
| Guidewire ClaimCenter | REST API integration using Guidewire Cloud API for claim creation, document attachment, and status updates. Webhook subscriptions for claim state changes. Batch file integration fallback for high-volume scenarios. | high | 8-12 weeks |
| Duck Creek Claims | Duck Creek API Suite for claim intake and document management. Event-driven integration using Duck Creek's webhook capabilities. Support for both cloud and on-premises deployments. | high | 8-12 weeks |
| Legacy Policy Administration Systems | Batch file integration using secure SFTP with PGP encryption. Scheduled polling for policy data retrieval. Message queue buffer for decoupling. | medium | 4-6 weeks |
| Document Management Systems (FileNet, Documentum, SharePoint) | Native connectors for document storage and retrieval. Metadata synchronization for search and compliance. Version control integration for audit trail. | low | 3-4 weeks |
ROI Framework
ROI is driven by reduced claims processing time enabling same-day FNOL, decreased manual data entry effort for adjusters, and improved customer retention by addressing the 45% switching rate due to slow service[1]. The framework uses conservative automation assumptions (65-75%) that should be validated during the parallel processing phase before finalizing business case projections.
Key Variables
Example Calculation
Build vs. Buy Analysis
Internal Build Effort
Internal build requires 24-36 months with a team of 10-15 engineers including ML specialists (multimodal vision expertise is scarce), compliance experts familiar with GDPR/CCPA/IFRS 17, and integration developers with Guidewire/Duck Creek experience. Key challenges include multimodal AI expertise (limited talent pool), ongoing model maintenance and retraining, and keeping pace with regulatory changes. Estimated build cost $3-5M with significant ongoing investment ($500K-1M annually) for model updates, compliance changes, and infrastructure operations.
Market Alternatives
Shift Technology
$500K-1.5M annually depending on volume and modulesEstablished insurance AI vendor with strong fraud detection and claims automation capabilities. Best fit for organizations prioritizing fraud detection alongside document processing, particularly those with existing Shift relationships or simpler compliance requirements.
- • Proven insurance industry expertise with large customer base
- • Strong fraud detection capabilities integrated with claims processing
- • Established compliance certifications and audit history
- • Less flexibility for custom compliance requirements across multiple jurisdictions
- • May require significant configuration for non-standard document types
- • Platform approach may not fit organizations with unique integration requirements
Tractable
$300K-800K annuallySpecialized in visual AI for damage assessment, particularly auto claims. Best fit for auto-focused insurers prioritizing damage photo processing and repair cost estimation over broad document automation.
- • Industry-leading accuracy for vehicle damage assessment
- • Fast implementation for auto claims use case
- • Strong partnerships with repair networks
- • Limited coverage for non-auto document types (medical bills, policy documents)
- • Less comprehensive compliance automation for multi-jurisdictional requirements
- • Narrower use case may require additional solutions for full claims automation
Hyperscience
$400K-1M annuallyGeneral-purpose intelligent document processing with insurance vertical capabilities. Best fit for organizations with broader document automation needs beyond claims, seeking a single platform for multiple use cases.
- • Broad document type coverage and strong OCR capabilities
- • Enterprise-grade security and compliance certifications
- • Applicable beyond claims to underwriting and policy servicing
- • Less insurance-specific optimization out of the box
- • May require more customization for claims-specific workflows and fraud detection
- • General-purpose positioning means less depth in insurance domain
Our Positioning
KlusAI's approach is ideal for insurers requiring deep customization for unique document types, multi-jurisdictional compliance requirements (particularly complex GDPR/CCPA/IFRS 17 combinations), or integration with legacy core systems that don't fit standard platform connectors. We assemble teams with the specific expertise needed—whether that's IFRS 17 specialists, Guidewire integration experts, or regional compliance knowledge—rather than forcing a one-size-fits-all platform. This flexibility is particularly valuable for global insurers with complex regulatory landscapes, those with proprietary document formats not well-served by standard solutions, or organizations that require on-premises deployment for data sovereignty reasons.
Team Composition
KlusAI assembles specialized teams tailored to each engagement, drawing from our network of vetted professionals with relevant insurance, AI, and compliance expertise. Team composition scales based on implementation scope and client capacity for knowledge transfer. The roles below represent a typical full-scale implementation; smaller engagements may combine roles or use fractional allocation.
| Role | FTE | Focus |
|---|---|---|
| Solution Architect | 1.0 | Overall architecture design, compliance framework, integration patterns, and technical decision-making. Leads technical workstreams and serves as primary technical point of contact. |
| ML Engineer (Vision/NLP) | 1.5 | Vision model deployment, fine-tuning on insurance documents, confidence calibration, and ongoing model optimization. Responsible for achieving accuracy targets. |
| Integration Developer | 1.0 | Core system integration with Guidewire/Duck Creek, API development, and legacy system adapters. Responsible for reliable data flow between AI platform and claims systems. |
| Compliance Specialist | 0.5 | GDPR, CCPA, and IFRS 17 compliance implementation, audit trail design, and regulatory documentation. Works with customer legal/compliance team. |
| Change Management Lead | 0.5 | Adjuster training program design, embedded champion coordination, adoption tracking, and resistance management. Critical for sustainable adoption. |
Supporting Evidence
Performance Targets
90%+ for structured documents, 80%+ for unstructured
65-75% of eligible claims
70-80% reduction in document intake time
Zero findings in first regulatory examination
Team Qualifications
- KlusAI's network includes professionals with insurance claims processing and core system integration experience across Guidewire, Duck Creek, and legacy platforms
- Our teams are assembled with specific expertise in multimodal AI deployment, including self-hosted vision model fine-tuning and MLOps for regulated industries
- We bring together technical specialists and regulatory compliance professionals with experience implementing GDPR, CCPA, and IFRS 17 controls in financial services contexts
Source Citations
45% of customers switch due to slow service
"45% of customers switch due to slow service"exact
Manual data entry from photos of damage, medical bills, and policy documents creates significant bottlenecks
directionalstrict regulatory demands for data privacy and auditability under GDPR, CCPA, and IFRS 17
directionalCurrent solutions achieve only 57% automation for simple claims
"achieving 57% automation"exact
leaving complex documents reliant on manual review
directionalReady to discuss?
Let's talk about how this could work for your organization.
Schedule a Consultation
Pick a date that works for you
Times shown in your local timezone ()
Prefer email? Contact us directly
Almost there!
at
Your details
at
You're all set!
Check your email for confirmation and calendar invite.
Your booking is confirmed! Our team will reach out to confirm the details.
Your consultation
· min
( team time)
Quick Overview
- Technology
- Computer Vision
- Complexity
- high
- Timeline
- 5-7 months
- Industry
- Finance