The Problem
Coding errors and undercoding cause significant revenue leakage in healthcare, with hospitals losing up to 3% of net revenue annually from charge capture errors alone. Common issues like mismatched modifiers and undercoding lead to claim denials, costing practices thousands in lost revenue.
These challenges are exacerbated by complex payer-specific requirements, evolving ICD-10 and CPT guidelines, and high denial rates from documentation gaps or medical necessity issues. Manual processes struggle to keep pace, resulting in substantial financial dips and compliance risks under HIPAA and coding standards.
Current solutions often rely on reactive denial management, with AI tools showing up to 70% error reduction potential but limited by incomplete predictive capabilities and lack of proactive forecasting across DRGs, CPT, and ICD-10 combinations.
Our Approach
Key elements of this implementation
-
Predictive analytics models analyzing historical coding patterns, claim denials, and payer rules with anomaly detection for high-risk encounters
-
HIPAA-compliant infrastructure with end-to-end encryption, audit trails for all predictions, and ICD-10/CPT validation against official guidelines
-
Seamless integration with EHRs like Epic and Cerner via API connectors, plus data residency controls for global compliance
-
Human-in-the-loop workflows with confidence scoring, phased rollout, and coder training to mitigate adoption risks and ensure accuracy
Get the Full Implementation Guide
Unlock full details including architecture and implementation
Implementation Overview
This implementation addresses the significant revenue leakage caused by coding errors in healthcare organizations, where hospitals lose up to 3% of net revenue annually from charge capture errors alone[2]. The solution combines predictive analytics with HIPAA-compliant infrastructure to identify high-risk encounters before claim submission, enabling proactive intervention rather than reactive denial management.
The architecture centers on a multi-layered prediction engine that analyzes historical coding patterns, claim denial data, and payer-specific rules to generate risk scores for each encounter. AI-driven approaches have demonstrated up to 70% error reduction potential[1], and our implementation targets 60-70% detection recall (identifying 60-70% of actual errors) with precision above 75% (minimizing false positives that waste coder time). This distinction is critical: we optimize for catching errors while respecting coder workflow efficiency.
A core design principle is human-in-the-loop validation throughout the prediction workflow. Rather than automating coding decisions, the system surfaces high-risk encounters to certified coders with confidence scores and supporting evidence, enabling informed review. This approach addresses the change management challenges inherent in healthcare AI adoption while building coder trust and ensuring clinical accuracy. The phased rollout includes dedicated change management activities, coder involvement in model validation, and union consultation where applicable.
UI Mockups
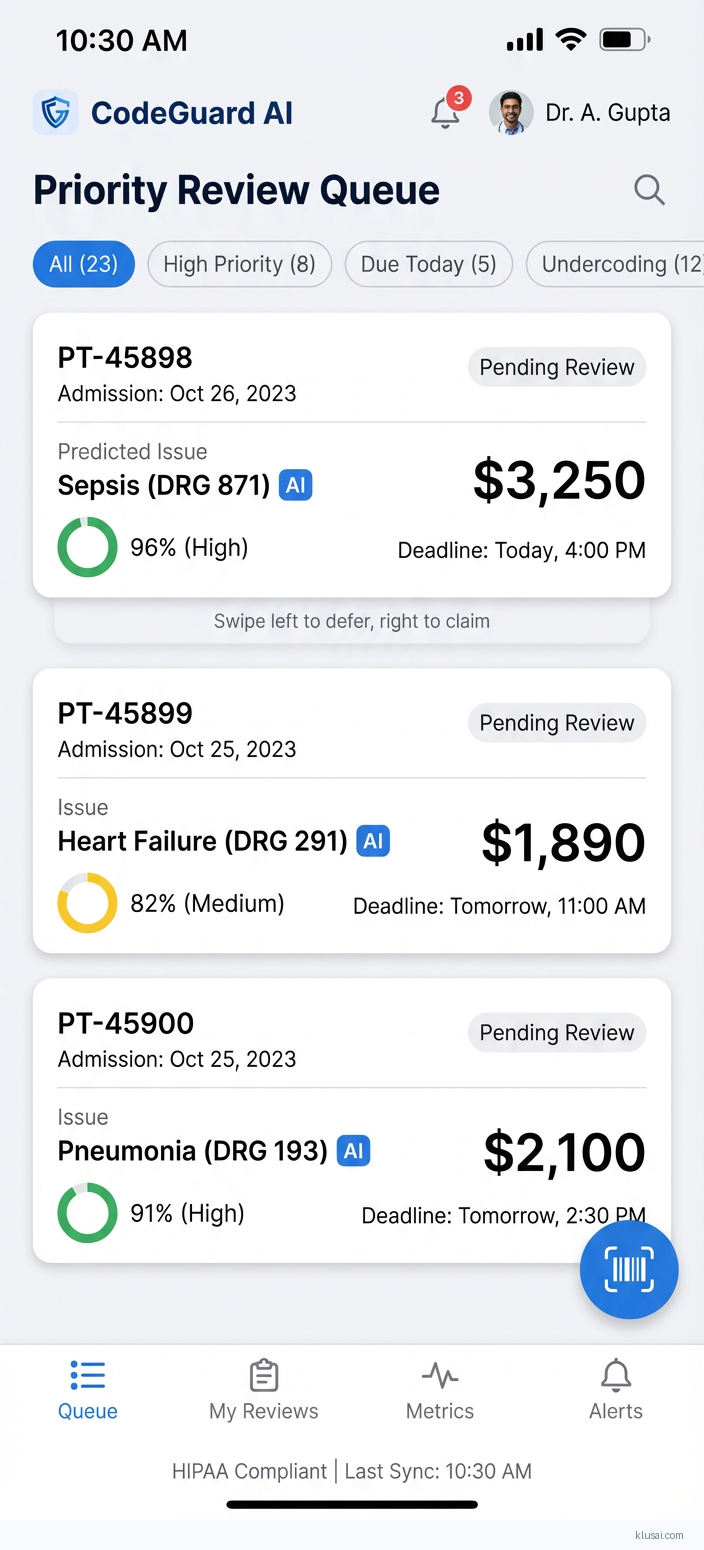
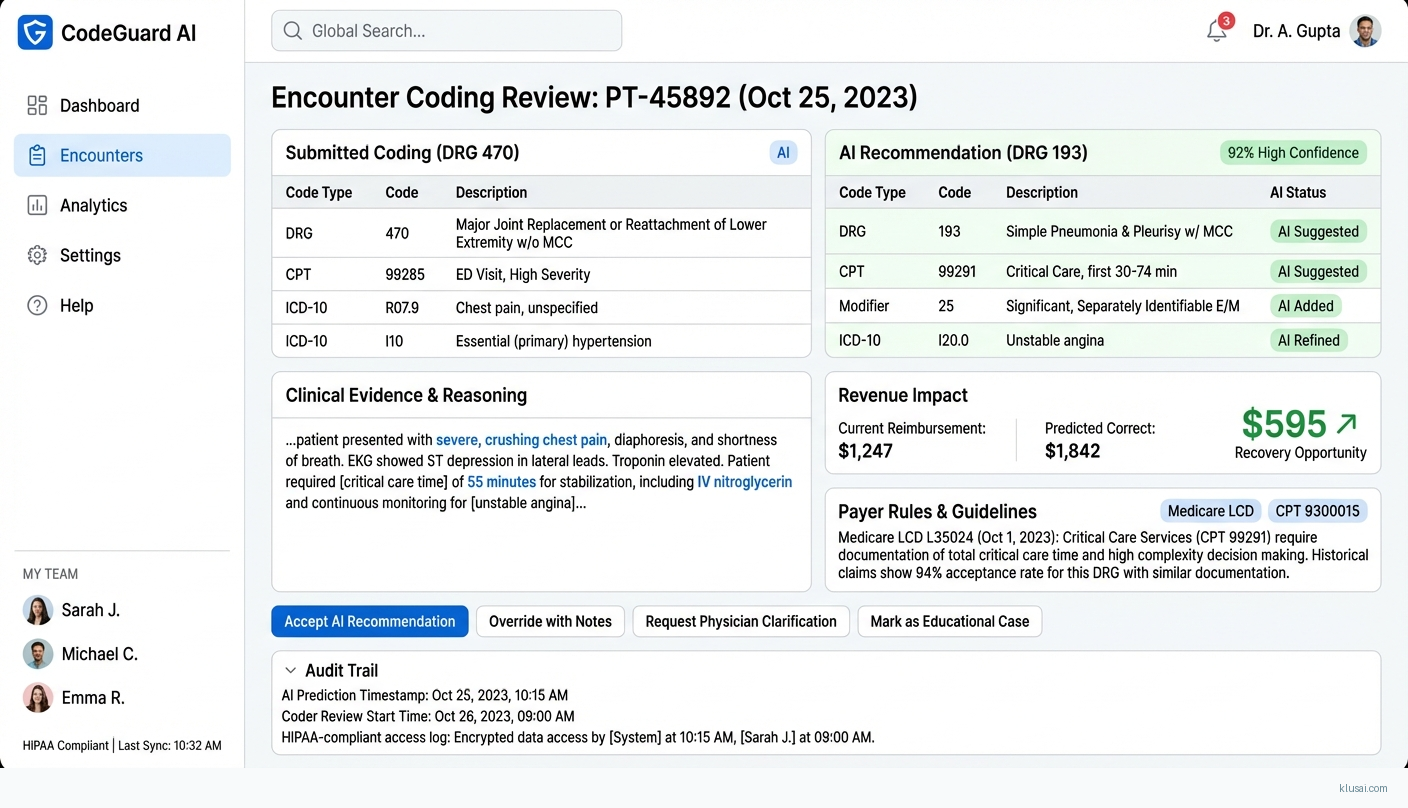
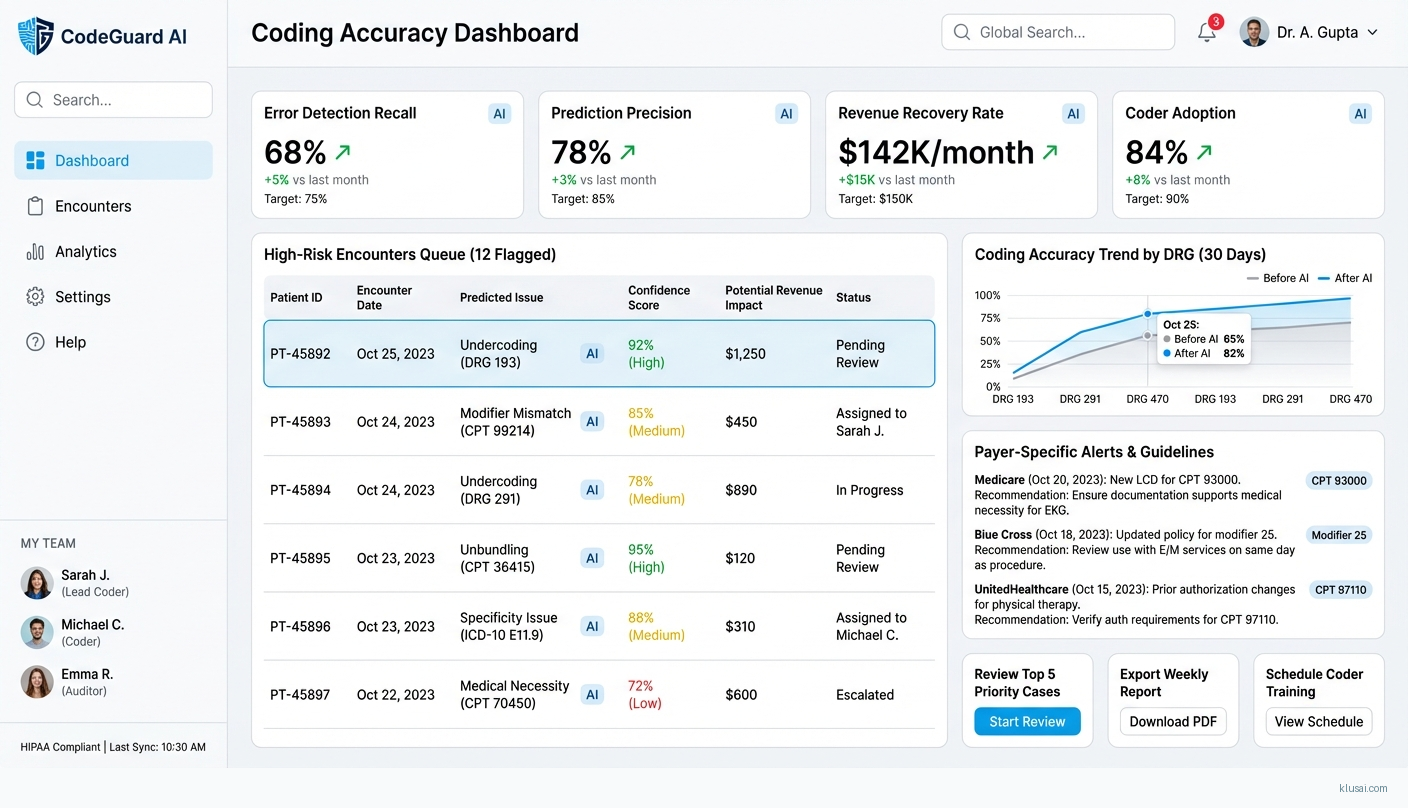
System Architecture
The architecture follows a layered approach with clear separation between data ingestion, prediction processing, integration services, and user-facing applications. All layers operate within a HIPAA-compliant security boundary with end-to-end encryption, comprehensive audit logging, and role-based access controls meeting OCR (Office for Civil Rights) requirements.
The data layer ingests encounter data from EHR systems, historical claims from practice management systems, and denial data from clearinghouses. A dedicated data quality engine addresses the clinical documentation variability common in healthcare—handling missing fields, inconsistent terminology, and provider-specific documentation patterns. This preprocessing is critical given that data quality issues typically consume 40-60% of healthcare AI implementation effort.
The prediction layer employs an ensemble approach combining rule-based payer logic with machine learning models trained on organization-specific denial patterns. The rule engine handles deterministic payer requirements (modifier combinations, medical necessity edits), while ML models identify subtle patterns across DRG, CPT, and ICD-10 combinations that correlate with denials. A multi-payer rule management component maintains separate rule sets per payer, with conflict resolution logic when guidelines differ.
The integration layer provides bidirectional connectivity with EHR systems through certified API connectors, supporting both real-time (pre-submission) and batch (end-of-day review) workflows. The architecture scales from pilot (single department, 1,000 encounters/month) to enterprise deployment (multi-facility, 100,000+ encounters/month) through horizontal scaling of prediction services and partitioned data storage.
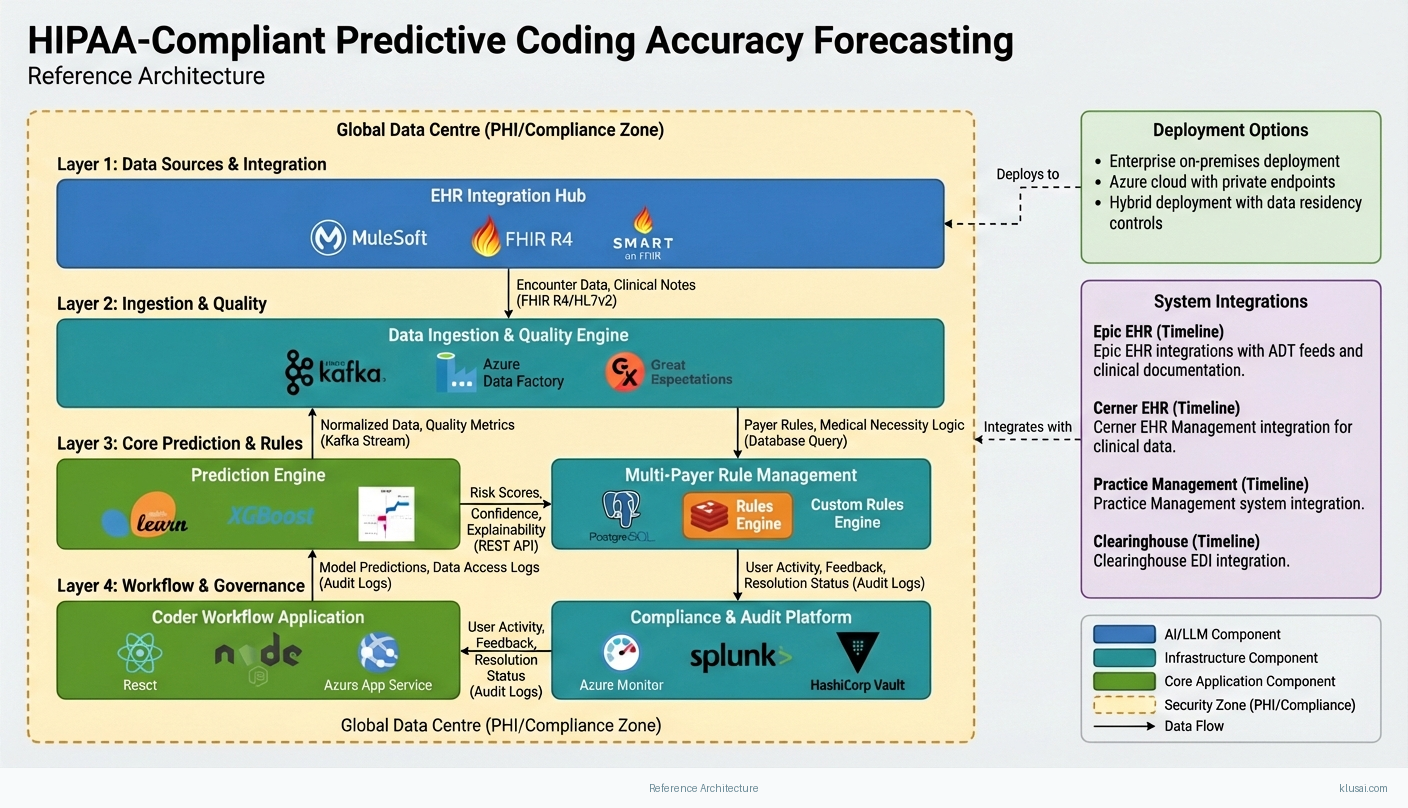
Key Components
| Component | Purpose | Technologies |
|---|---|---|
| Data Ingestion & Quality Engine | Ingests encounter data from multiple sources, performs data quality validation, normalizes clinical documentation variability, and maintains data lineage for audit compliance | Apache Kafka Azure Data Factory Great Expectations |
| Prediction Engine | Generates risk scores for encounters using ensemble of rule-based payer logic and ML models, with confidence scoring and explainability for coder review | Python/Scikit Learn Xgboost Shap |
| Multi-Payer Rule Management | Maintains payer-specific coding rules, medical necessity requirements, and modifier logic with version control and conflict resolution across payers | Postgresql Redis Custom Rules Engine |
| EHR Integration Hub | Provides certified API connectivity to Epic, Cerner, and other EHR systems with bi-directional data flow and workflow embedding | Mulesoft Fhir R4 Smart On Fhir |
| Coder Workflow Application | Web-based interface for coders to review flagged encounters, view risk explanations, provide feedback, and track resolution status | React Node.Js Azure App Service |
| Compliance & Audit Platform | Maintains comprehensive audit trails, manages PHI access logging, supports OCR compliance requirements, and enables security incident investigation | Azure Monitor Splunk Hashicorp Vault |
Technology Stack
Implementation Phases
Phase 1: Foundation & Security Approval
Complete security review and obtain EHR integration approval (Epic/Cerner security questionnaire, BAA execution)
- • Complete security review and obtain EHR integration approval (Epic/Cerner security questionnaire, BAA execution)
- • Establish HIPAA-compliant infrastructure with OCR-aligned audit logging and access controls
- • Conduct stakeholder alignment including coder union consultation and change management planning
- Signed BAA and completed security assessment documentation
- Deployed infrastructure with passing HIPAA security controls validation
- Change management plan with coder involvement strategy and training curriculum outline
Phase 2: Data Pipeline & Initial Model Development
Build production-ready data pipeline with quality validation and lineage tracking
- • Build production-ready data pipeline with quality validation and lineage tracking
- • Develop initial prediction models using historical denial data with baseline accuracy validation
- • Establish multi-payer rule engine with top 5 payers by volume
- Operational data pipeline processing live encounter data with <2% data quality rejection rate
- Trained prediction models with documented accuracy metrics (target: 75%+ precision, 60%+ recall on held-out test set)
- Payer rule engine covering 80%+ of claim volume
Phase 3: Pilot Deployment & Validation
Deploy to pilot department with 2,000-5,000 encounters/month volume
- • Deploy to pilot department with 2,000-5,000 encounters/month volume
- • Validate prediction accuracy against actual denial outcomes with coder feedback integration
- • Refine confidence thresholds and workflow based on pilot learnings
- Pilot deployment with 50+ coders actively using system
- Validated accuracy metrics with 90-day denial outcome correlation
- Refined model with pilot feedback incorporated and documented improvement metrics
Phase 4: Enterprise Rollout & Optimization
Expand deployment to additional departments/facilities based on pilot success
- • Expand deployment to additional departments/facilities based on pilot success
- • Establish model monitoring and drift detection for ongoing accuracy maintenance
- • Transfer operational knowledge to internal team for sustained operation
- Enterprise deployment covering 80%+ of organizational encounter volume
- Operational runbook with model retraining procedures and drift response protocols
- Trained internal team capable of day-to-day operations and Tier 1 support
Key Technical Decisions
Should prediction models use deep learning or traditional ML approaches?
Gradient boosting models provide strong performance on structured claims data with better explainability for coder trust-building. Deep learning adds complexity without proportional benefit for tabular data, though may be valuable for unstructured clinical notes. Starting simpler enables faster iteration and easier debugging during initial deployment.
- SHAP-based explainability enables coders to understand why encounters are flagged, building trust and adoption
- Faster training cycles (hours vs days) enable rapid iteration during model development
- May miss complex patterns in clinical documentation that transformer models could capture
- Requires feature engineering effort that deep learning would automate
How should the system handle conflicting payer rules for the same encounter?
Automated conflict resolution risks incorrect coding decisions. By surfacing conflicts with both payer requirements visible, coders can make informed decisions while the system captures the resolution pattern for future learning. This approach maintains compliance while building organizational knowledge.
- Maintains coder control over ambiguous situations, reducing compliance risk
- Captured resolutions become training data for future model improvement
- Increases coder workload for multi-payer encounters
- Requires more sophisticated UI to display conflicting requirements clearly
Should the system integrate in real-time or batch mode with EHR systems?
Real-time integration requires deeper EHR embedding and more stringent latency requirements. Batch processing (end-of-day or pre-submission queue) provides 80% of the value with significantly lower integration complexity. This approach enables faster time-to-value while real-time capabilities mature.
- Batch integration can proceed during EHR security approval process using file-based transfer
- Lower latency requirements simplify infrastructure and reduce cost
- Coders review flagged encounters separately from coding workflow rather than in-context
- Some errors may be submitted before batch review catches them
How should model accuracy targets be defined and measured?
The 70% error reduction potential cited in industry research[1] refers to overall error reduction when AI assists coders, not raw model detection rate. Our targets reflect realistic ML performance while acknowledging that human-AI collaboration achieves the full potential. Precision is prioritized alongside recall because excessive false positives erode coder trust and adoption.
- Clear, measurable targets enable objective pilot success evaluation
- Balanced precision/recall respects coder time while catching meaningful errors
- 30-40% of errors will not be flagged, requiring continued reliance on existing QA processes
- 90-day measurement lag delays feedback on model improvements
Integration Patterns
| System | Approach | Complexity | Timeline |
|---|---|---|---|
| Epic EHR | FHIR R4 APIs via Epic App Orchard certification for encounter data extraction; SMART on FHIR for embedded workflow integration; file-based ADT/charge feeds as interim during certification | high | 12-16 weeks (including App Orchard certification) |
| Cerner EHR | FHIR R4 APIs via Cerner Code certification; HL7v2 ADT feeds for real-time encounter notifications; Cerner Millennium integration for workflow embedding | high | 10-14 weeks (including Code certification) |
| Practice Management / Billing Systems | Batch file integration (837/835 formats) for claims and remittance data; direct database connectivity where available; clearinghouse API integration for denial data | medium | 4-6 weeks |
| Clearinghouse (Change Healthcare, Availity) | API integration for real-time eligibility and prior authorization status; batch 835 remittance feeds for denial tracking; denial reason code enrichment | medium | 6-8 weeks |
ROI Framework
The ROI model quantifies value through three primary drivers: recovered revenue from prevented coding errors, reduced rework costs from lower denial rates, and coder efficiency gains from AI-assisted prioritization. Healthcare organizations typically experience 3-15% revenue leakage from coding errors[1][2], with the 3% figure representing charge capture errors specifically[2]. Conservative assumptions are used throughout, with actual results validated during pilot phase before enterprise projections.
Key Variables
Example Calculation
Build vs. Buy Analysis
Internal Build Effort
Internal build requires 18-24 months with a dedicated team of 6-8 FTEs including ML engineers (2-3), healthcare informaticists (1-2), integration specialists (2), and project management (1). Key challenges include EHR integration complexity (expect 4-6 months for Epic/Cerner security approval alone), HIPAA compliance infrastructure buildout, and ongoing model maintenance. Estimated internal investment of $1.2-1.8M before production deployment, with ongoing operational costs of $400-600K annually for model maintenance, infrastructure, and dedicated staff. Most organizations underestimate the change management effort required—coder adoption and trust-building often determine success or failure more than technical accuracy.
Market Alternatives
3M CodeAssist
$150-300K annually depending on volume and modulesEnterprise-grade coding assistance integrated with 3M's encoder and grouper products; best suited for organizations already invested in 3M's revenue cycle ecosystem seeking incremental improvement
- • Mature product with extensive payer rule library refined over decades
- • Deep integration with 3M 360 Encompass encoder reduces workflow friction
- • Strong compliance pedigree with established healthcare customer base
- • Less flexibility for custom model development or organization-specific patterns
- • May require broader 3M platform adoption to realize full value
- • Predictive capabilities more limited than purpose-built ML approaches
Optum/Change Healthcare Coding Solutions
$200-400K annually for enterprise deploymentLarge-scale revenue cycle platform with AI-assisted coding; leverages clearinghouse data for denial prediction across broad payer network
- • Extensive payer connectivity through clearinghouse relationships
- • Comprehensive revenue cycle integration beyond coding
- • Strong denial prediction based on massive industry-wide claims dataset
- • Complex implementation for organizations not already on Optum platform
- • Less customization flexibility for unique organizational workflows
- • Potential concerns about data sharing given Optum's payer relationships
AKASA
$100-250K annually based on transaction volumeModern AI-first platform focused on revenue cycle automation; strong in denial prediction and workflow automation with unified AI approach
- • Purpose-built AI architecture with modern technology stack
- • Flexible deployment and strong API-first integration approach
- • Rapid innovation cycle as AI-native company
- • Newer entrant with less extensive payer rule libraries than established vendors
- • May require complementary solutions for full coding workflow
- • Less proven at very large health system scale
Our Positioning
KlusAI's approach is ideal for organizations requiring customized prediction models tailored to their specific payer mix, specialty focus, and coding patterns—particularly where off-the-shelf solutions have underperformed or where unique compliance requirements exist. We assemble teams with the exact expertise needed for each engagement, whether that's deep Epic integration experience, specialized clinical NLP capabilities, or specific regulatory knowledge for multi-regional operations. This flexibility is particularly valuable for academic medical centers with unique documentation patterns, specialty-focused practices with niche coding requirements, or organizations building internal AI capabilities alongside implementation. Our methodology emphasizes change management and coder adoption from Day 1, with dedicated resources for stakeholder engagement, training development, and union consultation where applicable—addressing the human factors that often determine success or failure of healthcare AI initiatives.
Team Composition
KlusAI assembles specialized teams tailored to each engagement, combining technical ML expertise with healthcare domain knowledge and change management capabilities. Team composition scales based on organization size and complexity, with the configuration below representing a typical mid-size health system engagement. For organizations with strong internal technical teams, KlusAI can provide targeted expertise (e.g., healthcare informatics, EHR integration) rather than full-stack delivery.
| Role | FTE | Focus |
|---|---|---|
| Project Lead / Solutions Architect | 1.0 | Overall delivery accountability, architecture decisions, stakeholder management, and risk mitigation |
| ML Engineer | 1.5 | Model development, training pipeline construction, accuracy optimization, and production deployment |
| Healthcare Informaticist | 0.75 | Clinical validation, coding accuracy assessment, payer rule interpretation, and coder workflow design |
| Integration Engineer | 1.0 | EHR connectivity, data pipeline development, API integration, and security implementation |
| Change Management Specialist | 0.5 | Coder adoption strategy, training development, stakeholder communication, and union engagement |
Supporting Evidence
Performance Targets
60-70%
>75%
30-40% of identified leakage
>80% of flagged encounters reviewed within 24 hours
Team Qualifications
- KlusAI's network includes professionals with healthcare revenue cycle implementation experience across major EHR platforms including Epic and Cerner
- Our teams are assembled with ML engineers experienced in healthcare AI applications and HIPAA-compliant infrastructure deployment
- We bring together clinical informaticists, certified coders, and technical specialists tailored to each organization's specific payer mix and specialty focus
Source Citations
up to 70% error reduction
"AI can reduce coding errors by up to 70%"exact
up to 3% of net revenue annually from charge capture errors
"hospitals lose up to 3% of net revenue annually due to charge capture errors"exact
AI models had overall accuracy of 87.9% and 84.2%
"overall accuracy... of 87.9% and 84.2%"range
Ready to discuss?
Let's talk about how this could work for your organization.
Schedule a Consultation
Pick a date that works for you
Times shown in your local timezone ()
Prefer email? Contact us directly
Almost there!
at
Your details
at
You're all set!
Check your email for confirmation and calendar invite.
Your booking is confirmed! Our team will reach out to confirm the details.
Your consultation
· min
( team time)
Quick Overview
- Technology
- Predictive Analytics
- Complexity
- high
- Timeline
- 4-6 months
- Industry
- Healthcare