The Problem
Long processing times for policy documents frustrate new customers and contribute to churn in insurance.
Challenges include ensuring jurisdiction-specific compliance across global markets like GDPR data handling, NAIC form requirements, and Solvency II reporting, while pulling accurate data from underwriting systems without errors that risk fines or rework.
Current solutions reduce processing time by up to 40% through partial automation but rely heavily on manual reviews for compliance, struggling with multi-jurisdictional complexity and lacking full integration with core systems.
Our Approach
Key elements of this implementation
-
Hybrid rule-engine + RAG-LLM: Rules handle NAIC form validation/Solvency II zoning; LLM assembles personalized text from jurisdiction-specific libraries
-
Compliance controls: GDPR pseudonymization, immutable audit trails for all frameworks, data residency via zoned processing, automated regulatory reporting
-
Integrations: API connectors to Guidewire/Insurity PAS, CRM, e-signature; human review for non-deterministic outputs
-
9-12 month rollout: Pilot with 1 jurisdiction (60-day parallel run), executive training for 50 users, phased global expansion with 20% buffer for integrations
Implementation Overview
This implementation addresses the critical challenge of policy document processing times that frustrate customers and contribute to churn[1], while ensuring compliance across global regulatory frameworks. The hybrid architecture separates deterministic compliance logic (handled by a rules engine) from flexible document assembly (handled by RAG-augmented LLM), enabling auditability for regulators while delivering personalized policy documents.
The approach integrates with existing Policy Administration Systems (Guidewire, Insurity) through event-driven APIs, pulling policyholder data and coverage details while maintaining data residency requirements through zoned processing. A confidence scoring mechanism routes low-confidence outputs to human reviewers, ensuring compliance teams maintain oversight of non-deterministic decisions. The architecture includes immutable audit trails satisfying GDPR Article 30 record-keeping, NAIC Model Audit Rule requirements, and Solvency II Pillar 3 reporting obligations.
Expected outcomes include 25-40% reduction in document processing time[2], decreased error-related rework through automated validation, and improved regulatory audit readiness through comprehensive logging. The 12-15 month timeline (extended from initial 9-12 month estimate to accommodate legacy PAS integration complexity) includes a 60-day parallel run in a single jurisdiction before phased global expansion, with explicit discovery phases to assess PAS customization depth and legal/actuarial approval workflows.
UI Mockups
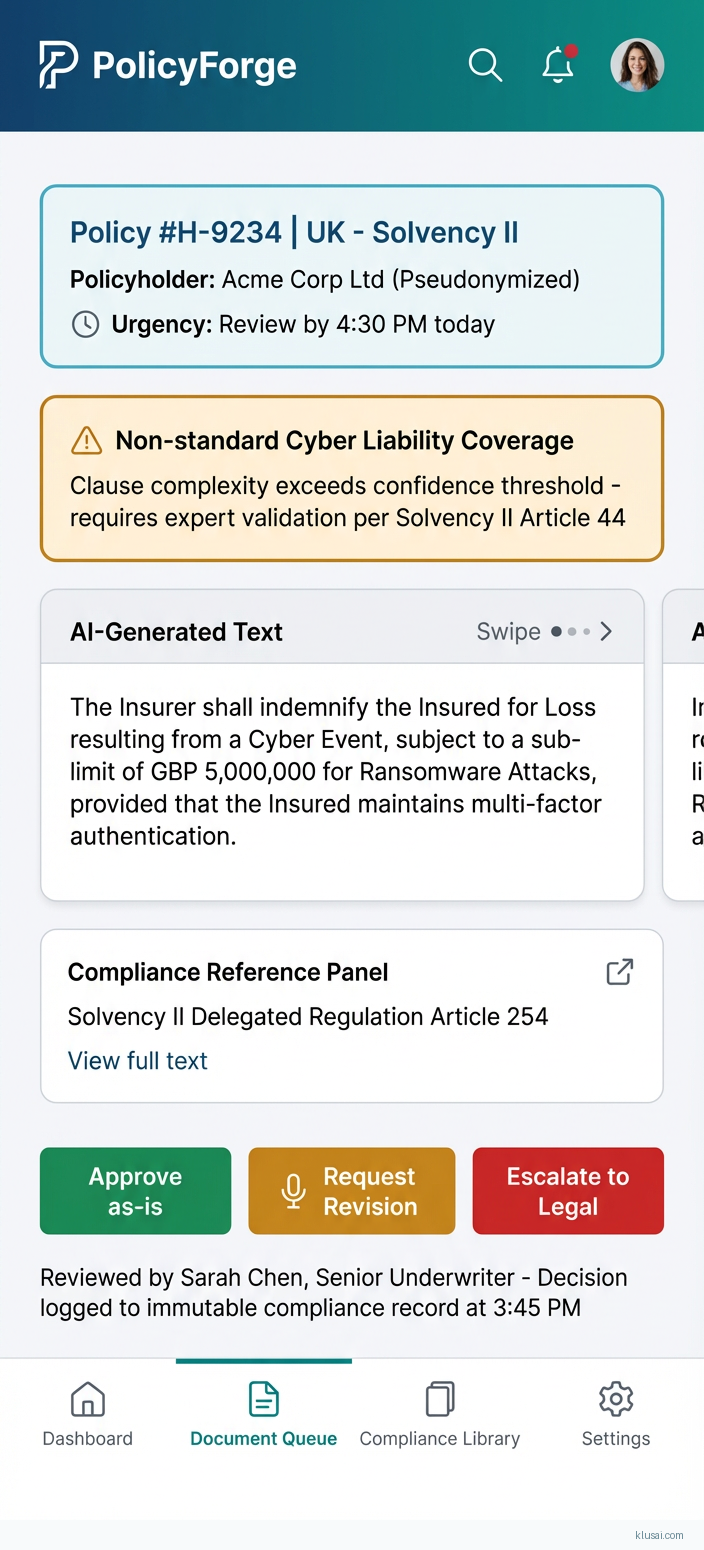
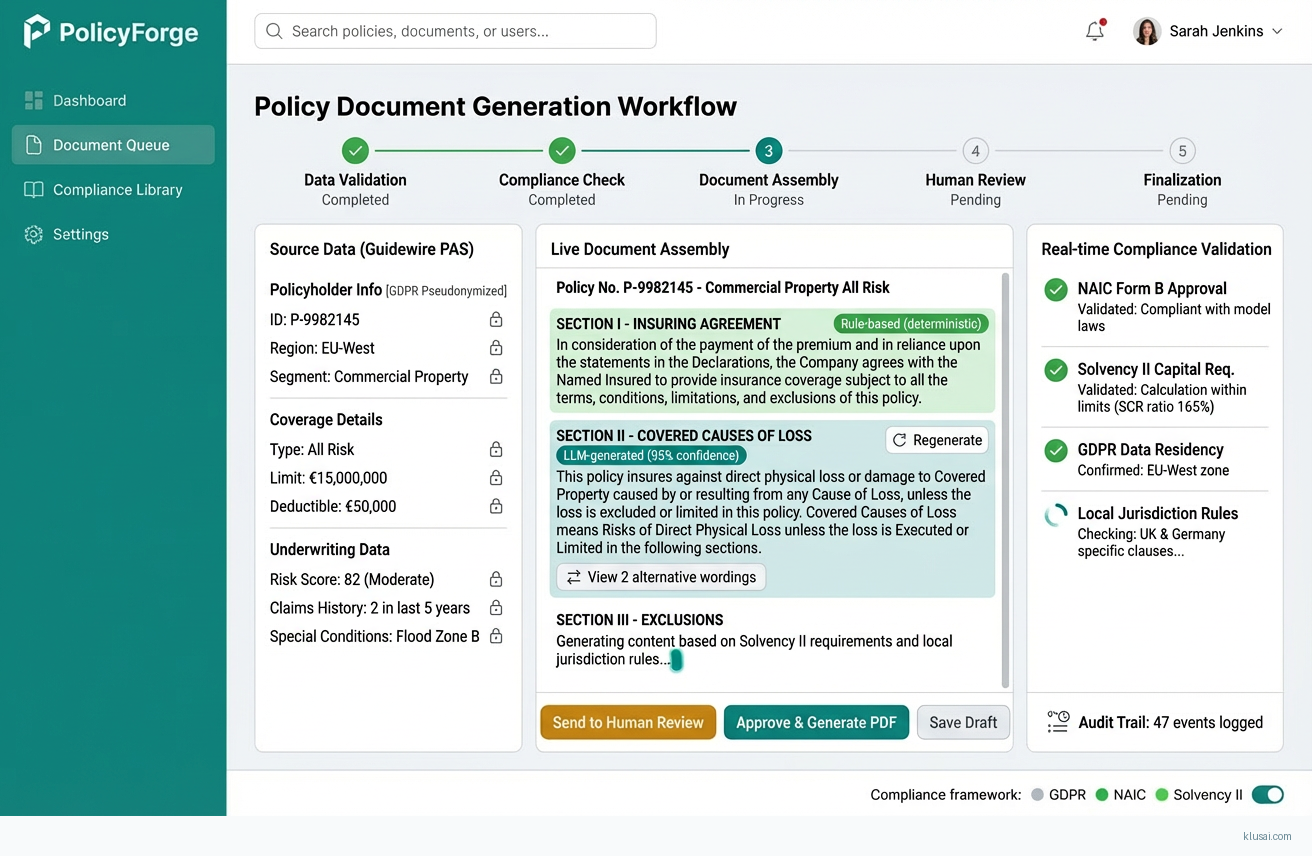
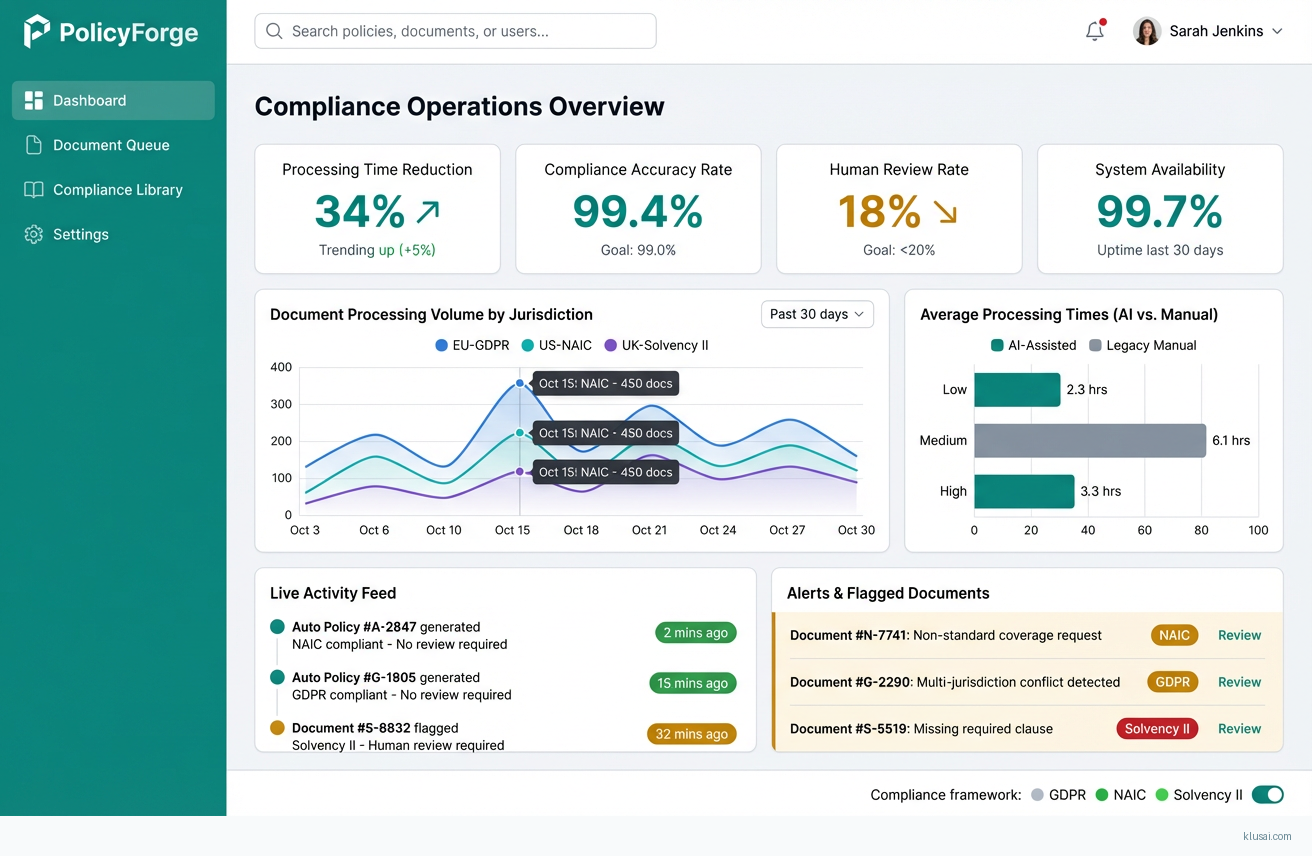
System Architecture
The architecture follows a layered approach with clear separation between compliance enforcement, document generation, and system integration. The Compliance Rules Layer handles deterministic regulatory requirements: NAIC form field validation, Solvency II capital reporting calculations, and GDPR data handling rules. This layer produces audit-ready logs for every decision, enabling regulators to trace exactly why specific document elements were included or excluded.
The Document Generation Layer combines a vector store of jurisdiction-specific clause libraries with an LLM for natural language assembly. The RAG pipeline retrieves relevant clauses based on policy type, jurisdiction, and coverage details, while the LLM assembles these into coherent, personalized documents. A confidence scoring mechanism (threshold: 0.85) determines whether outputs proceed automatically or require human review. Embedding models chunk clause libraries by semantic meaning (512-token chunks with 50-token overlap) using sentence-transformers, stored in Pinecone with metadata filtering for jurisdiction and document type.
The Integration Layer provides API connectors to Policy Administration Systems (Guidewire PolicyCenter, Insurity Policy Decisions), CRM systems, and e-signature platforms (DocuSign, Adobe Sign). Event-driven architecture ensures real-time triggering when policies are bound or endorsed, with message queuing (Azure Service Bus) providing resilience against downstream system unavailability. Data residency is enforced through regional processing zones—EU data processed in Azure West Europe, US data in Azure East US, with no cross-border data transfer for PII.
The Observability Layer provides comprehensive monitoring including LLM latency tracking, confidence score distribution analysis, and model drift detection. Structured logging captures all inputs, outputs, and intermediate decisions for audit purposes, with separate retention policies for operational logs (90 days) and compliance audit logs (7 years). Alerting integrates with existing incident management workflows through PagerDuty and Slack.
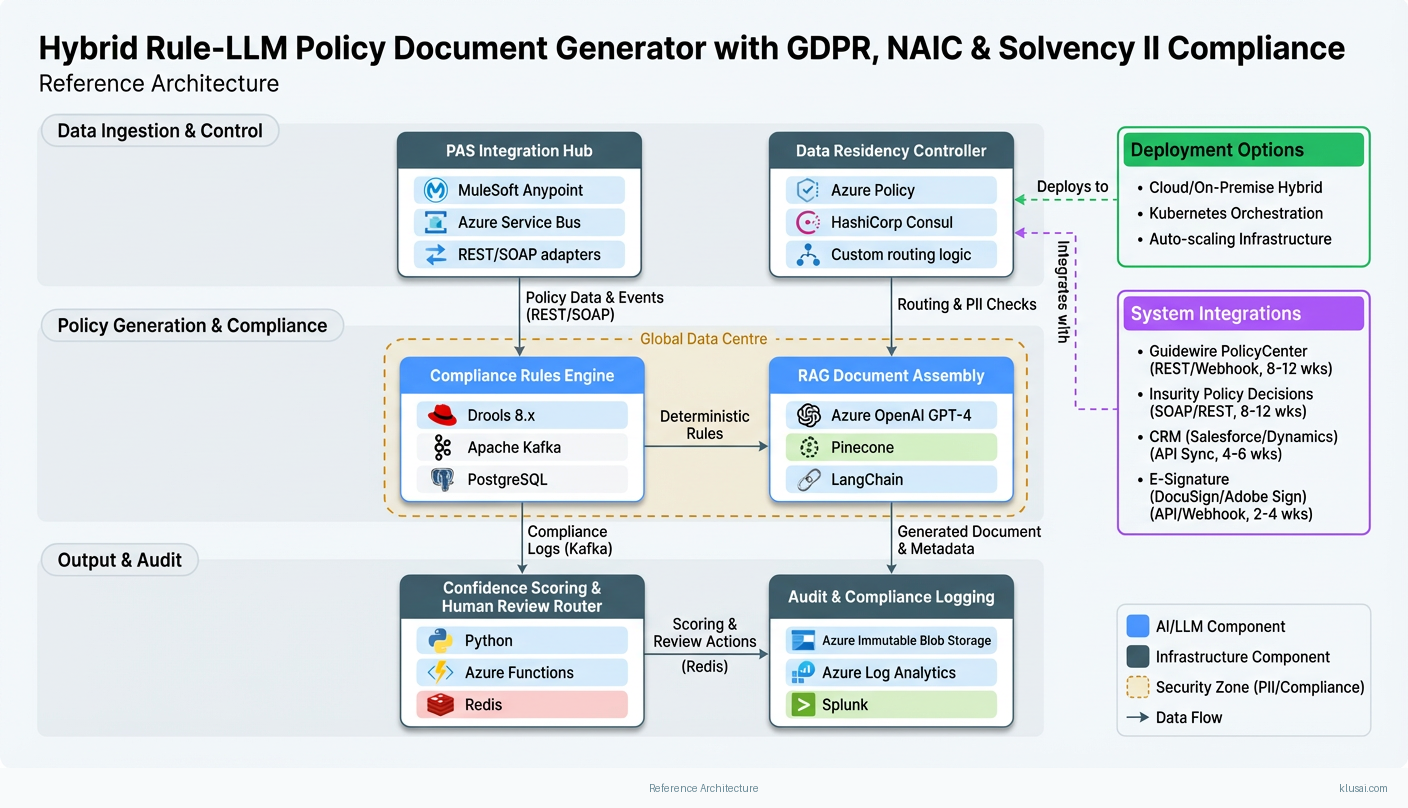
Key Components
| Component | Purpose | Technologies |
|---|---|---|
| Compliance Rules Engine | Enforces deterministic regulatory requirements across GDPR, NAIC, and Solvency II frameworks with full audit trail | Drools 8.X Apache Kafka Postgresql |
| RAG Document Assembly | Retrieves jurisdiction-specific clauses and assembles personalized policy documents using LLM | Azure Openai Gpt 4 Pinecone Langchain |
| Confidence Scoring & Human Review Router | Evaluates LLM output confidence and routes low-confidence documents to appropriate reviewers | Python Azure Functions Redis |
| PAS Integration Hub | Bi-directional integration with Guidewire and Insurity policy administration systems | Mulesoft Anypoint Azure Service Bus Rest/Soap Adapters |
| Audit & Compliance Logging | Immutable audit trail for regulatory compliance across all frameworks | Azure Immutable Blob Storage Azure Log Analytics Splunk |
| Data Residency Controller | Enforces regional data processing requirements and prevents cross-border PII transfer | Azure Policy Hashicorp Consul Custom Routing Logic |
Technology Stack

Implementation Phases
Discovery & Foundation
Complete PAS integration assessment including customization depth analysis and data model mapping
- • Complete PAS integration assessment including customization depth analysis and data model mapping
- • Establish compliance rule library for pilot jurisdiction with legal and actuarial sign-off
- • Deploy core infrastructure with data residency controls and audit logging
- PAS Integration Assessment Report with complexity scoring and timeline adjustments
- Signed-off compliance rule set for pilot jurisdiction (including actuarial review for rate-affecting rules)
- Infrastructure deployed with security review completed and penetration testing scheduled
Core Development & Integration
Implement hybrid rule-LLM document generation pipeline with confidence scoring
- • Implement hybrid rule-LLM document generation pipeline with confidence scoring
- • Complete PAS integration with bi-directional data flow and error handling
- • Build human review workflow with routing to compliance, legal, and actuarial queues
- Functional document generation pipeline processing test policies end-to-end
- PAS integration certified by vendor (Guidewire/Insurity) with production-ready error handling
- Human review interface deployed with role-based routing and SLA tracking
Pilot & Parallel Run
Execute 60-day parallel run in pilot jurisdiction comparing AI-generated vs. manual documents
- • Execute 60-day parallel run in pilot jurisdiction comparing AI-generated vs. manual documents
- • Train 50 users including operations staff, compliance reviewers, and supervisors
- • Validate compliance with regulatory audit simulation
- Parallel run analysis report with accuracy metrics, processing time comparison, and exception analysis
- Trained user cohort with competency certification and feedback incorporated
- Regulatory audit simulation completed with findings remediated
Global Expansion & Optimization
Expand to additional jurisdictions with jurisdiction-specific rule sets and clause libraries
- • Expand to additional jurisdictions with jurisdiction-specific rule sets and clause libraries
- • Optimize model performance based on production feedback and drift detection
- • Establish ongoing operations including model monitoring and rule maintenance processes
- Production deployment in 3-5 additional jurisdictions with compliance certification
- Model performance optimization report with accuracy improvements documented
- Operations runbook and handover to internal teams completed
Key Technical Decisions
Should we use a single LLM for all jurisdictions or jurisdiction-specific fine-tuned models?
Fine-tuning per jurisdiction creates maintenance burden as regulations change and requires significant training data per jurisdiction. RAG approach allows rapid updates to clause libraries without model retraining, and prompt templates can be version-controlled with legal/compliance approval workflows.
- Faster time to new jurisdictions (weeks vs. months for fine-tuning)
- Easier compliance audit trail—clause sources are explicit in retrieval
- May require more sophisticated prompt engineering for complex jurisdictions
- Slightly higher inference costs due to longer context windows
How should confidence scoring determine human review routing?
Single threshold approach either over-routes (reducing efficiency gains) or under-routes (creating compliance risk). Separate thresholds allow calibration based on risk profile of each document section, with compliance-critical sections held to higher standards.
- Optimizes human review effort by routing to appropriate expertise
- Allows different risk tolerances for different document sections
- More complex to calibrate and maintain threshold settings
- Requires clear definition of which sections map to which reviewer type
What embedding model and chunking strategy for the clause library RAG?
512-token chunks balance semantic coherence of insurance clauses with retrieval precision. Overlap prevents clause boundaries from splitting key concepts. Metadata filtering is essential for multi-jurisdictional deployment to prevent cross-jurisdiction clause contamination.
- Well-tested embedding model with strong performance on legal/insurance text
- Metadata filtering enables precise jurisdiction control
- May require re-chunking if clause library structure changes significantly
- Ada-002 costs higher than open-source alternatives (but lower operational risk)
How to handle data residency requirements across global jurisdictions?
GDPR Article 44+ restrictions on cross-border data transfer require technical enforcement, not just policy. Regional deployment adds infrastructure complexity but is essential for compliance and reduces regulatory risk significantly.
- Technical enforcement of data residency reduces compliance risk
- Enables future expansion to additional regions (APAC, etc.)
- Higher infrastructure costs due to regional duplication
- More complex deployment and monitoring across regions
Integration Patterns
| System | Approach | Complexity | Timeline |
|---|---|---|---|
| Guidewire PolicyCenter | Event-driven integration using Guidewire Cloud API (REST) for policy data retrieval, with webhook notifications for policy bind/endorse events triggering document generation. MuleSoft handles data transformation between Guidewire data model and internal canonical model. | high | 8-12 weeks |
| Insurity Policy Decisions | SOAP/REST hybrid integration using Insurity's standard APIs for policy retrieval, with polling-based trigger detection for systems without webhook support. Message queuing provides resilience for batch processing scenarios. | high | 8-12 weeks |
| CRM (Salesforce/Dynamics) | Bi-directional sync for customer data and document delivery status using standard CRM APIs. Document generation status updates flow back to CRM for agent visibility. OAuth 2.0 authentication with refresh token management. | medium | 4-6 weeks |
| E-Signature (DocuSign/Adobe Sign) | API integration for document delivery and signature workflow initiation. Webhook callbacks update document status upon signature completion. Template mapping handles jurisdiction-specific signature requirements. | low | 2-4 weeks |
ROI Framework
ROI is driven by reduction in document processing time, decreased error-related rework, and improved customer experience leading to reduced early-stage churn. The framework quantifies time savings for operations and compliance staff while accounting for platform and maintenance costs.
Key Variables
Example Calculation
Build vs. Buy Analysis
Internal Build Effort
Internal build would require 18-24 months with a team of 8-12 FTEs including ML engineers, compliance specialists, integration developers, and legal/actuarial reviewers. Key challenges include developing jurisdiction-specific compliance expertise across GDPR, NAIC, and Solvency II frameworks, building and maintaining rule libraries with appropriate approval workflows, and ongoing model fine-tuning. Estimated internal build cost: £1.2-1.8M over 2 years, plus ongoing maintenance of £300-400K annually. Primary risk is lack of insurance-specific AI implementation experience leading to extended timelines and compliance gaps.
Market Alternatives
Guidewire Document Production
Included in Guidewire licensing or £50-100K annual add-onNative integration for Guidewire customers; strong for standard US policy forms and workflows
- • Seamless integration with Guidewire PolicyCenter
- • Pre-built templates for common US policy types
- • Vendor-supported compliance for US markets
- • Limited flexibility for non-standard documents or complex endorsements
- • Weaker support for non-US regulatory frameworks (GDPR, Solvency II)
- • No LLM-based personalization capabilities
Docugami
£100-200K annually based on document volumeAI-powered document understanding and generation; strong for commercial insurance document analysis
- • Advanced document AI capabilities for complex commercial policies
- • Good handling of unstructured document ingestion
- • Modern API-first architecture
- • Requires significant customization for regulatory compliance workflows
- • Less mature multi-jurisdictional support
- • Limited pre-built insurance integrations
Custom LLM Implementation (Internal)
£500K-1M implementation plus £200-300K annual maintenanceMaximum flexibility but highest effort and risk; suitable for organizations with strong ML teams
- • Full control over model selection, fine-tuning, and architecture
- • No vendor dependencies or licensing constraints
- • Can be tailored exactly to internal workflows
- • Requires deep ML expertise to build and maintain
- • Compliance certification burden falls entirely on internal team
- • Longer time to value (24+ months typical)
- • Risk of key person dependencies
Our Positioning
KlusAI's approach is ideal for organizations requiring multi-jurisdictional compliance (GDPR, NAIC, Solvency II) with the flexibility to adapt to evolving regulatory requirements. We assemble teams combining technical AI expertise with insurance domain knowledge, providing a faster path to production than internal builds while offering more customization than packaged solutions. Our hybrid rule-LLM architecture specifically addresses the auditability requirements that pure LLM solutions struggle to meet, with explicit human review workflows for compliance, legal, and actuarial oversight.
Team Composition
KlusAI assembles specialized teams tailored to each engagement, combining technical AI expertise with insurance domain knowledge. The composition below represents a typical team structure for this implementation scope, with flexibility to adjust based on client capabilities and PAS complexity.
| Role | FTE | Focus |
|---|---|---|
| Solution Architect | 1.0 | Overall architecture design, integration patterns, technical decision-making, and stakeholder alignment |
| ML/LLM Engineer | 1.5 | RAG implementation, prompt engineering, confidence scoring, embedding optimization, and model monitoring |
| Integration Developer | 1.0 | PAS integration, API development, data pipeline implementation, and error handling |
| Compliance/Rules Engineer | 0.75 | Compliance rule implementation, regulatory requirement translation, audit trail design |
| Change Management Lead | 0.5 | User adoption strategy, training program design, stakeholder engagement, feedback incorporation |
Supporting Evidence
Performance Targets
25-40% reduction in average processing time
>99% accuracy on compliance-critical fields
<20% of documents requiring human review post-stabilization
99.5% availability during business hours
Team Qualifications
- KlusAI's network includes professionals with insurance technology implementation experience across policy administration, claims, and underwriting systems
- Our teams are assembled with specific expertise in regulatory compliance frameworks including GDPR data protection, NAIC model regulations, and Solvency II reporting requirements
- We bring together ML engineers experienced in production LLM deployments with insurance domain specialists who understand policy document workflows and compliance requirements
Source Citations
Long processing times for policy documents frustrate new customers and contribute to churn
directionalreduce processing time by up to 40%
"reduced document processing time by 40%"exact
ensuring jurisdiction-specific compliance... NAIC form requirements
directionalReady to discuss?
Let's talk about how this could work for your organization.
Schedule a Consultation
Pick a date that works for you
Times shown in your local timezone ()
Prefer email? Contact us directly
Almost there!
at
Your details
at
You're all set!
Check your email for confirmation and calendar invite.
Your booking is confirmed! Our team will reach out to confirm the details.
Your consultation
· min
( team time)
Quick Overview
- Technology
- Large Language Models
- Complexity
- high
- Timeline
- 9-12 months
- Industry
- Finance